
#문자열 곱하기
a="python"
a*2
'pythonpython'
#문자열 길이
a="life is too short"
len(a)
파이썬 문자열 - index 0부터 붙음
뒤에서 부터 셀때 - -붙이고 뒤에서부터 센 숫자로 계산한다.
+) -0은 -를 붙여도 0이기 때문에 a[0]하고 같은 값이 된다.
#문자열 슬라이싱 [a:b]=a<=x<b (b 이전까지만 슬라이싱한다)
a="life is too short"
a[0:4]
#문자열을 0~3 인덱스 까지 슬라이싱한다
a[19:-7]
#문자열을 19~-8 까지 출력한다 -7은 포함하지 않음- 슬라이싱 할때 끝을 생략하면 끝까지, 처음을 생략하면 처음부터 출력한다.
- 파이썬 문자열의 요소값은 변경할수 있는 값이 아니다. 따라서 immutable한 자료형이라고 부른다.
#문자열 포매팅
-> 문자열 안에 정수, 실수 등을 삽입하고 싶을 때 사용한다.
number =3
"I eat %d number" % number
number=10
day="three"
"I ate %d apple, I was sick for %s days" %(number,day)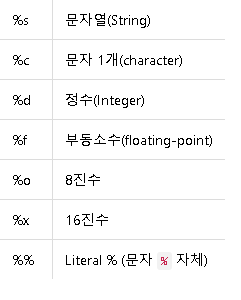
%s 값은 어떤 형태의 값이든 변환해 넣을 수 있다.
#format 함수를 이용한 formatting
"I eat {0} apples".format(3)
"I eat {0} apples".format("five")
"I ate {0} apples. so I was sick for {1} days".format(number,day)
#인덱스 말고 변수 이름으로 넣는 방법도 있다.
"I ate {number} apples. so I was sick for {day} days".format(number=3,day=3)
"I ate {0} apples. so I was sick for {day} days".format(3,day=3)
#문자열 관련 함수들
a="hobby"
a.count('b') #b의 개수를 세어준다
a="Python is the best choice"
a.find('b') #b의 index를 찾아서 리턴한다, 존재하지 않으면 -1
a.index('b') #같은 역할을 한다. 대신 존재하지 않으면 오류 트리거
a="hi"
a.upper()
a.lower()
#a를 대문자/소문자로 바꿔준다
a=" hi"
a.lstrip() #a의 왼쪽 공백 삭제해줌
a="hi "
a.rstrip() #a의 오른쪽 공백 삭제
a="life is too short"
a.replace("Life","Your leg")
'your leg is too short'
a="Life is to short"
a.split()
['life' 'is' 'too' 'short'] #default로 공백 기준으로 나눈다
a="a:b:c:d"
a.split(':') #특정값이 있으면 괄호 안의 값을 구분자로 해서 문자열을 나눠준다.
['a','b','c','d']
#파이썬 List
: 어떠한 데이터 타입도 호환 가능하며, single variable에 multiple item을 저장하기 위해 고안되었다. [ ] 으로 둘러싸여있다.
또, list는 아이템 삽입, 삭제등 변화가 가능하다.
a=[]
a=list()
c=['life','is','too','short']
d=[1,2,'life,'is']
e=[1,2,['life','is']] #리스트 안에 리스트를 집어넣을 수도 있다.
->모든 list값은 indexing된다.
e[2][0] #'life'를 리턴한다.
e[2] #life,is를 포함한 리스트를 포함한다.
#List slicing&operation
#List Slicing은 string과 동일한 방식이다.
a=[1,2,3,4,5]
a[0:2] #[1,2]
a[2:] #[3,4,5]
#Add list
a=[1,2,3]
b=[4,5,6]
a+b
#repeat list
a=[1,2,3]
a*3=[1,2,3,1,2,3,1,2,3]
#lenght of list
len(a)=3
#change item
a=[1,2,3]
a[2]=4
a==[1,2,4]
#delete list item
a=[1,2,3]
del a[1]
a==[1,3]
#item append
a=[1,2,3]
a.append(4)
a==[1,2,3,4]
a.append([5,6]) #item 째로 append한다.
a==[1,2,3,4,[5,6]]
a.sort()
a.sort(reverse=True) #내림차순
#리스트 뒤집기
a.reverse()
#index 찾기
a.index(3) #-> 3의 index리턴
#insert item
a=[1,2,3]
a.insert(0,4) #0번째 index에 4 삽입
a==[4,1,2,3]
#remove specific item
a=[1,2,3,1,2,3]
a.remove(3)
a=[1,2,1,2]
#pop()
a=[1,2,3]
a.pop() #가장 마지막 element return후에 delete
a.pop(1) #x index를 리턴하고 삭제한다.
#count()
a=[1,2,3,1]
a.count(1)
#Tuple
list와 거의 비슷하지만, 두가지가 다르다. ( )으로 둘러싸여있다는 것과. 아이템 변경,추가,삭제등이 불가능하다.
t1=()
t2=(1,)
t3=(1,2,3)
t4=(1,2,3,(4,5)
#indexing, slicing, addition, multiplication, length등 함수는 가능
#추가, 삭제, 변경등은 불가능
#Dictionary
- {Key1:value1},{Key2:value2},{key3:value3}....등등 각 요소가 key-value쌍으로 이루어져 있다. Key에는 불변하는 값을 사용하고 Value에는 변하는 값과 변하지 않는 값 모두 사용할 수 있다.
- value에는 List값도 넣을 수 있다.
a={1:'a'}
a[2]='b' #이런 식으로 선언해주면 자동으로 insert됨
a['name']='ashie'
a[3]=[1,2,3]
a=={1:'a',2:'b','name':'ashie',3:[1,2,3]}
del a[key] #key를 입력하면 지정한 key-value쌍을 지워준다.
#key를 통해 value 얻기
grade={'pey':10,'julliet':99}
grade['pey']==10
- key는 고유값이므로 중복되는 값이 존재할 경우 나머지 key-value값이 모두 무시된다.
- key에 리스트는 쓸수 없으나 튜플은 쓸 수 있다. -> key는 무조건 불변한 값만 가능. 같은 원리로 key에 딕셔너리도 불가능하다.
# Dictionary 함수
#key list 만들기
a={'name':'pey', 'phone':'01012345555','birth':'1118'}
a.keys()
#key만 모은 dict_keys 객체를 리턴한다.
for k in a.keys():
print(k)
#a.keys()값을 전부 프린트하게 된다.
#value list도 동일한 방법
a.values()
#key,value 쌍 얻기
a.items()
#key-value 쌍을 튜플로 묶은 dic_items 객체를 리턴한다\
#key-value쌍 모두 삭제
a.clear()
#key로 value 얻기
a.get('name') #a['name']과 동일한 값이지만 오류 발생한다는게 다름
#해당 key가 딕셔너리 안에 있는지 조사 'in'
'name' in a
#set
- 집합 자료형 -> set 키워드를 통해서 만들 수 있다.
- 중복을 허용하지 않으며(중복을 제거하는 filter역할), 순서가 없다
- set의 값을 인덱싱으로 접근하려면 리스트나 튜플로 변환 후에 해야 한다.
s1=set([1,2,3])
s1={1,2,3}
s2=set('Hello')
s2={'H','l','o','e'} #중복 제거&순서 없음
#순서 없어 인덱싱 못하므로 리스트나 튜플로 변환후 인덱스로 접근해야함
l2=list(s2)
l2[0]=='H'
lt2=tuple(s2)
lt2[1]='l'
-교집합 : s1&s2 or s1.intersection(s2)
-합집합 : s1 } s2 or s1.union(s2) -> 중복된 값은 한개씩만 출력됨
-차집합 : s1-s2 or s1.difference(s2) -> s1에는 있고 s2는 없는 값 출력
#값 1개 추가
s1=set([1,2,3])
s1.add(4)
s1=={1,2,3,4}
#값 여러개 추가
s1.update([4,5,6])
s1=={1,2,3,4,5,6}
#특정값 제거
s1.remove(2)
s1=={1,3,4,5,6}
#Boolean
: True & False 값 두가지만 갖는다.
: 문자열, 넘버, list, tuple, set, dictionary등 거의 모든 자료형은 null일 때나 empty 상태를 제외하고 모두 true이다.
: [],{},(),0,None 등은 모두 false
#변수 선언 방식
- Camel CAse : 단어마다 첫번째 단어를 제외하고 첫글자는 대문자 : myVariableName
- pascalcase : 모든 단어 첫글자를 대문자 : MyVariableName
- snakecase : 문자 구분자를 _ 로 한다 : my_variable_name
# 변수 생성 방식
a,b=('python','life')
(a,b)='python','life'
[a,b]=['python','life'] #튜플이나 리스트로 변수 여러개 한번에 선언 가능
a=3
b=5
a,b=b,a #swap이 한줄로 가능
#for문의 기본 구조
for 변수 in 리스트(or 튜플,문자열):
수행문장~
test_list=['one','two','three']
for i in test_list:
print(i)
a=[(1,2),(3,4),(5,6)]
for (first,last) in a:
print(first+last)
marks=[90,25,67,45,80]
for mark in marks:
number=number+1
if mark<60:
print("%d 번 학생은 불합격입니다" % number)
else:
print("%d번 학생은 합격입니다" % number)
#for문은 숫자 리스트를 자동으로 만들어주는 range 함수와 함께 사용하는 경우가 많다.
for i in range(0,10):
print(i)
for number in range(len(marks)):
#처음 범위를 안지정하면 자동으로 0~부터 끝 인덱스까지 진행된다.
#list 내포를 사용하면 좀더 효율적으로 문제를 풀 수 있다.
a=[1,2,3,4]
result=[num*3 for num in a]
[표현식 for 항목1 in 반복가능객체1 if 조건문 1
for 항목2 in 반복가능객체1 if 조건문 2
for 항목3 in 반복가능객체1 if 조건문 3...]
#함수
parameter : 매개변수, 함수와 메서드 입력 변수 명 (실체가 변수)
argument: 전달인자, 함수와 메서드의 입력 값 (실체가 value)
#key-value syntax 로 argument 전달
def add(a,b)
return a+b
result=add(a=3,b=7)
#몇개의 argument가 전달될지를 모를때
def add_many(*args):
result=0
for i in args:
result=result+i
return result
result=add_many(1,2,3)
result=add_many(1,2,3,45)
#둘을 혼합해서 사용 가능
def add_mul(choice, *args)
#keyword parameter는 함수를 호출할때 인자 값뿐만 아니라 그 이름까지 명시적으로 지정해서 전달하는ㄴ 방법
def add(a=0,b=0,c=0)
return a+b+c
add()
#명시적으로 0이 대입되어있는 상태
# 키워드 파라미터가 몇개 올지 모를때
def add (**kwargs)

-lambda expression
-> lambda parameter1,parameter2,.... : expression
add=lambda a,b:a+b (def add와 같은 역할..)
-한줄에 결과값 출력
print(i,end=' ')
-파일 읽는 여러가지 방법
1) readline 사용 : 파일을 한줄한줄 읽어옴
f=open('file.txt','r')
while True:
line=f.readline()
if not line:break
print(line)
f.close()
#readline()은 더이상 읽을 줄이 없을 경우 빈 문자열' '을 리턴한다
2) readlines: 모든 내용을 한꺼번에 읽어옴. 각각의 줄을 요소로 갖는 리스트로 돌려줌
f=open('file.txt','r')
lines=f.readlines()
for line in lines:
line=line.strip() #줄 끝의 줄 바꿈문자를 제거한다.
print(line)
f.close()3)read: 파일의 내용 전체를 문자열로 돌려줌.
data=f.read()
print(data)
f.close()
-파일에 새로운 내용 추가
: 이미 존재하는 파일을 w 모드로 열면 기존 내용이 전부 사라지게 된다. 'a' 모드로 열어서 write해야 기존 파일 뒤에 이어서 작성이 가능하다.
f=open("c:/doit/새파일.txt",'a')
for i in range(11,20)
data="%d번째 줄입니다"%i
f.write(data)
f.close()
#Object VS Instance
클래스로 만든 객체를 해당 클래스의 instance라고도 한다.
-> 즉 인스턴스라는 말은 특정 객체가 어떤 클래스의 object인지 관계 위주로 설명할 때 사용된다.
a = Cookie()
일때, a는 객체, a는 Cookie클래스의 인스턴스라는 표현이 자연스러운 것.
# Self parameter
: c++에서 this랑 같은 역할 한다고 보면 됨
=> class의 current instance를 의미한다. class에 딸려있는 변수들을 사용하기 위함.
- 어떤 method이든 가장 첫번째에 와야 한다.
#Constructor
__init__(self) : 메소드를 통해서 객체가 만들어질때 실행된다.
#상속
parent class: base class
child class: 다른 클래스로부터 상속받은 클래스 class child(parent): 식으로 안에 넣어서 상속
-> 현존하는 클래스의 특징을 제거하지 않고 사용하기 위함이다
-> child class는 부모 클래스의 함수를 오버라이딩 할 수 있다.
#클래스 변수
: 모든 클래스로 만들어진 객체내에서 변경 없이 통용되는 변수를 의미한다
class 이름 선언부 다음에 바로 온다
#인스턴스 변수
method 변수 내에서 선언되며, 오직 그 인스턴스 내에서만 같은 값으로 사용된다.
'Computer Science > python' 카테고리의 다른 글
| 파이썬으로 순열 경우의 수 구하기 (0) | 2021.10.30 |
|---|---|
| Python에서의 Testing/Debugging (0) | 2021.10.24 |