
[시스템프로그래밍] 프로세스 생성과 실행
유닉스에서 프로세스는 사용자가 명령행에서 직접 프로그램을 실행해 생성하는 경우도 있지만, 프로그램 안에서 다른 프로그램을 실행해 생성하는 경우도 있습니다. 이렇게 프로그램에서 다른
12bme.tistory.com
1. 프로세스란?
: 현재 수행중인 프로그램으로 각각 프로세스는 address space 가 필요하다. heap, data, stack,text 영역으로 이루어져있다. active entity로 여러가지 상태를 올겨다니며 실행된다.
이때, 프로세스가 실행되고 종료되는 과정을 알아보도록 하자.
2. process creation
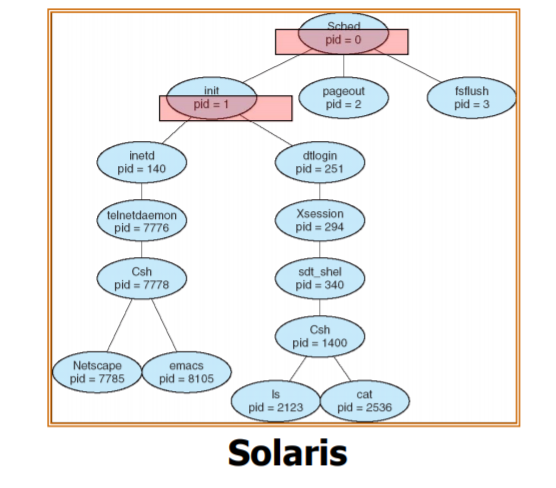
- process는 주로 트리 형태를 가진다. 프로세스마다 parent process에 의해 생성되기 때문이다.
pid= 프로세스 아이디이고, 윗 level에 있는 프로세스가 부모 프로세스라고 할 수 있다.
pid number를 모든 프로세스가 갖는다.
3. process creation하면서 issue는?
1) resource sharing option : 부모, 자식 프로세스가 resource를 어떻게 공유하는가?
=> child process가 부모 프로세스 의 자원을 일부 공유한다.
2) Execution option
1) parent와 child가 concurrently( 동시적으로) 실행된다.
2) 부모가 자식이 terminate 될때 까지 기다린다.
=> 둘중 하나가 상황에 따라 실행된다. 하지만 주로 부모가 기다린다.
3) address space
1) 자식 프로세스가 부모의 address space를 복제한다
2) 자식 프로세스가 duplicate한 address space에 새로운 프로그램을 로딩한다.
=> stack, heap, data space등등의 address space는 공유는 안된다. 자식 프로세스도 별도의 프로세스이기 때문.
4. Unix 나 Linux의 케이스에서는 어떠한가?
-> 프로세스를 생성하는 일은 : OS가 실행한다. fork() 함수 실행하여 오직 system call로만 process가 생성가능하다.
- fork system call을 통해 어떤 일이 발생하는가
1) Resource sharing
: parent and children이 file을 공유한다. 그렇지만 별도로 할당되어야 한 메모리나 cpu 부분등은 공유되지 않는다.
2) Execution
: 둘이 concurrently 하게 수행된다.
3) Address space
: 복제 되지만, 서로 다른 address space를 갖게 되고, 여기에 새로운 프로그램을 로딩한다.
+) 처음에는 같은 stack, local variable, heap, progream을 갖고, 여기에 자신만의 새로운 프로그램을 로딩한다.
4) call once, return twice
: fork() 함수의 특징은 부모에 의해서 호출된 후에, duplicate 할때 부모와 자식 프로세스를 구분하기 위해 return 값을 pid of child(0), pid to parent(pid of child) 두가지로 다르게 하여 구분한다.

1) fork 함수를 호출하고, 일단 address space를 duplicate 한다
2) 하지만 전형적으로 그 위에 새로운 프로그램을 overwrite하여 새롭게 로딩한다. (같을 수 없음)
=> duplicate해서 새롭게 로딩하지 않으면 모든 프로세스가 새로운 프로그램을 갖게 된다.
따라서 exec() system call을 호출하여 새로운 프로그램을 로딩한다.
=> exec()의 역할 : 프로그램을 새롭게 로딩하고, 프로그램을 초기화한다.
이때, 자식이 exec를 호출하면서 자식 프로세스가 다른 활동을 할 동안 많은 경우 자식 프로세스가 terminate하길 기다린다.
3) Reaping child process
: wait() system call을 호출해 부모 프로세스는 자식 프로세스가 terminate 되기를 기다린다.
이때, zombie process란
=> 거둬지지 않은 프로세스를 의미하고, 부모 프로세스가 wait함수를 호출하지 않은 경우에 자식이 terminate되었을 때 자식 프로세스는 zombie process로 빠진다.
< process 실제 create , terminate 과정>

1) 부모 프로세스가 fork() 함수를 호출해 address space를 child에게 duplicate한다. 따라서 같은 address space를 공유하게 되지만, 그 이후로 새로운 프로그램을 거기에 로딩하게 된다.
: 이때 child와 parent process를 구분하기 위해 return값을 다르게 한다. child에게는 0을 리턴하고, parent process에게는 child의 pid값을 리턴한다.
2) 이때 pid==0, 즉 child이면 exec함수를 호출해서 초기화 후에 새로운 프로그램을 로딩한다
3) parent process는 wait함수를 호출하고, 자식 프로세스가 terminate 될때 까지 기다린다. 이때 호출하지 않으면 자식 프로세스가 zombie 상태로 빠지게 된다.
<exec 함수 호출 이후에 child process에선 어떤 과정을 거치는가?>

1) 처음에는 부모 프로그램과 동일한 프로그램 갖고 있었지만, exec을 통해 /bin/ls 프로그램을 새로 overwrite하게 된다.
2) heap, stack이 초기화되고, program counter가 프로그램을 line by line으로 수행하게 된다.
child process가 exit함수를 통해 terminate될때까지 parent 함수는 wait 함수를 통해 기다리고 있게 된다.
3) child가 terminate되면 parent 가 wait 함수에서 벗어나 다음 line 명령을 실행한다.
Q) 왼쪽 함수가 wait 함수에서 기다리고 있는 동안 parent의 상태는?
: waiting 상태에 빠져있다. child process가 끝나면 ready 상태로 바뀌고, CPU가 해당 프로세스를 dispatch 하면 running state로 바뀌어서 밑 printf line 명령을 수행한다.
5. Process termination
: process가 terminate되는 방법에는 두가지가 존재한다.
1) exit() 함수를 통한 자발적 terminate
2) 다른 프로세스가 terminate해버리는 abort() 함수: 주로 자식 프로세스를 terminate할때 쓰인다.
- Exit()
: chlid process가 exit 함수를 호출하면, exit 을 호출한 자식 프로세스를 생성한 parent 프로세스에게 메세지를 전달한다. parent process에게 wait 함수 인자를 통해 메세지를 전달하고, 할당한 resource를 회수한다.
- Abort()
: 부모가 자식을 일부로 terminate한다.세가지 경우가 존재한다.
- 자식이 할당한 것 보다 많은 resource를 사용했을 때
- 자식 프로세스가 더이상 필요가 없을 때
- 부모 프로세스가 먼저 exiting 할때
: 보통 os는 parent process가 terminate 될때 자식 프로세스가 돌아가는 것을 허용하지 않는다. 따라서 모든 자식 프로세스가 terminate 되게 된다.
그렇지만 가끔 자식 프로세스만 유지되는 경우가 있는데, 부모가 terminate되고 자식만 남아있는 process를 orphan 프로세스라고 한다.
+) orphan process vs zombie process (헷갈리지 말 것!)
: orphan process는 부모가 먼저 terminate되고, 자식만 남아있는 프로세스를 의미하고, zombie 프로세스는 자식 프로세스가 terminate되었을때 부모가 wait process를 호출하지 않아서 이를 reap 하지 않은 경우이다.

=> 부모 프로세스가 먼저 terminate되었을 경우에 orphan process가 되는데, 이때 init process의 child process로 재할당 하게 된다.
- IPC (inter-process termination)
: 프로세스간에 communication이 필요한 이유가 무엇인가?
=> 많은 경우에 프로세스들이 병렬적으로 수행되어 하고자 하는 일을 달성하려고 할 때가 많다.
: 이러한 프로세스의 집합을 cooperating process라고 한다.
<=> 반대는 independent process로, 다른 프로세스의 영향을 받지 않는다.
-Process cooperation의 이점
1) Information Sharing
: shared file을 통해 resource의 낭비를 줄일 수 있다.
2) Computation speed-up
: parellel processing을 통해 컴퓨팅 속도를 향상시킬 수 있다.
<parellel과 concurrency의 차이 참고>
[프로그래밍] Concurrency, Parallelism 차이
Concurrency(병행성) 그리고 Parallelism(병렬성) 포스팅 원본출처는 http://egloos.zum.com/minjang/v/2517211 입니다. Concurrency는 프로그램의 성질이고 parallel execution은 기계의 성질이다. Concurrenty..
12bme.tistory.com
3) modularity
: 하나의 프로세스에 기능을 너무 많이 넣으면 프로세스가 너무 방대해질 수가 있다.
=> 여러개의 프로세스에 별도의 임무 부여할 시 프로세스의 모듈화가 용이하다. (편리한 일 처리 가능)
4) Convenience
: 하나의 프로세스는 시간이 오래 걸리는 반면에 cooperating하면 일을 한꺼번에 처리 가능하다.
<IPC>
: 여러 프로세스간 communicate가 어려운 이유는 각각의 process가 자기만의 address space를 갖고 있고, 다른 process의 address space를 갖고 있고, 다른 프로세스의 address space를 알 수 있는 방법이 없기 때문에 kernel의 도움이 필요하다.-> 커널에서 제공하는 매커니즘인 IPC의 도움이 필요하다.
1) Message passing
: 커널의 내부에 mailbox라는 data structure를 생성한다. 이를 통해 여러 프로세스간에 소통을 지원한다.
2) Shared memory
: 프로세스의 일부 영역을 shared memory로 설정하여 두 프로세스간에 소통한다.

- Typical example of IPC
1) Producer- Consumer problem
: cooperating process의 패러다임에 의하면, producer process는 consumer process에 의해 소비되는 information을 계속 생산한다.
: 이때 information이 buffer에 들어가게 된다.
1) unbounded buffer- 버퍼 사이즈에 한계가 없다
2) bounded buffer - 버퍼 사이즈에 정해진 사이즈가 있다.
=> 프로세스간 synchronization이 반드시 되야 하는데, 이때 필요하다.
=> producer- consumer problem은 주로 shared-memory를 사용할 때 발생한다.

=> buffer에서는 producer가 생산한 item을 저장한다. (unbounded buffer, bounded buffer)
=> 위의 예시에서는 버퍼 사이즈가 미리 10이라고 정해져 있다.
이때 각각의 item은 구조체로 정의되어있고, 버퍼는 producer process와 consumer process가 서로 공유하는 shared data 공간이 된다.
-> 버퍼가 비어있는 부분과 차있는 공간을 counter로 표시한다. emtpy상태일 때 시작은 둘다 같은 0을 가리키게 된다.

이때 item이 들어오거나 소비되면 in, out 이 이동하게 된다. 이를 spin lock mechanism이라고도 한다.

1. producer process
: 버퍼가 가득 찼다면 ( (in+1)% buffer_size==out) 일때면 아이템을 생산해도 저장할 공간이 없어서 while loop를 맴돈다. (in-> 버퍼가 비어있는 위치) 그리고 item이 차면 in 포인터가 하나 이동한다.
2. consumer process
: 버퍼가 비어있다면 in==out라면 더이상 소비할 프로세스가 없으므로 while loop를 맴돈다. 그리고 item을 consume할 수 있게 되면 out 포인터가 out+1 % buffer_size해서 하나 이동하게 된다.
(in, out 포인터가 궁극적으로는 같은 방향으로 움직인다. produce 할때는 in, consume 할 때는 out)
in-> 포인터가 비어있는 첫 위치, out- 포인터가 차 있는 첫 위치

=> shared memory의 핵심은 특정 프로세스가 다른 space의 일부를 공유영역으로 설정해서 다른 프로세스에게 오픈해 놓는 것이다. 그리고 shared memory를 attach하고 detach할 때는 커널의 도움이 필요하므로 system call을 호출한다.
1) 프로세스 B 가 shared 영역을 설정한다. < shgmet>
2) 프로세스 A가 공유 영역을 자신의 영역인 것 처럼 attach한다. <shmat>
3) 프로세스 B가 shared region에 write함수를 통해 "Shared region" 이라고 표시한다.
4) 프로세스 A가 read 함수를 통해 shared region을 읽어들인다.
5) 공유공간을 detach한다.
=> shared 공간에서 read/write 함수를 통해 동기화를 수행한다.
: 다른 프로세스의 주소 접근 권한도 없고, 확인도 불가하기 때문에 커널의 도움을 받아 일부 영역을 open하게 된다.
2) Message- Passing
--> P,Q가 소통하기를 원한다면 그들은
1) communication link를 우선 설정해야 한다.
2) send/recieve 함수를 통해서 메세지를 주고받아야 한다.
1. Establishing link (서로 다른 프로세스간 메세지 주고받음)
->communication link을 구현하면서 physical 적인 부분인 shared memory, hardware bus가 필요하다. 또 logical properties 부분인 mailbox 부분도 구현을 해주어야 한다.
1) Direct Communication
: 프로세스들은 데이터를 받는 process를 명시적으로 꼭 지정을 해주어야 한다.
Send (P, message): p에게 메세지를 보낸다, Recieve(Q, message): Q에게 메세지를 전달한다.

2) Indirect Communication
: 메세지들은 mailbox로부터 전송받고, 전송보내지게 된다. (port라고도 표현한다.)
각 mailbox들은 특정한 id가 존재하며 프로세스는 mailbox를 공유할 경우에만 communicate가 가능하다.
2. Direct Communication vs Indirect Communication
1) Direct Communication : 링크가 automatically하게 설정된다.
: direct 방식은 보내는 프로세스가 받는 프로세스를 반드시 (receiver) 명시해줘야 한다.
각각의 보내는 프로세스와 받는 프로세스에서는 하나의 링크밖에 존재할 수가 없다.
이때 각각의 pid를 갖고 있어 다른 프로세스임을 구분할 수 있다.
=> 가장 대표적인 mechanism은 pipe mechanism이다.
2) Indirect Communication: 중간에 메일박스와 같은 매개체가 존재한다.
: mailbox만 갖고 있다면 다양한 링크가 존재할 수 있고, 이 링크들이 여러개 프로세스와 공유될 수 있다.
-> 링크는 uni-directional하거나 bi-directional할 수 있다.
따라서 보다 더 자유롭고 보편적으로 사용되는 method이다.
=> 그렇지만 몇가지 이슈가 발생할 수 있다.
: 어떻게 링크가 설정되는가, 링크가 두개보다 많은 프로세스와 연관될 수 있는가, 링크의 용량은 얼마정도인가, 링크의 방향은 단방향인가 양방향인가...

1) link는 여러개의 프로세스들과 연관될 수 있다.
2) 각각의 프로세스 들은 여러개의 링크를 가질 수 있다. (ex : process 1,4는 mailbox 1,2를 둘다 사용한다.)
=> Indirect communication operation
: 거쳐야 되는 step이 몇가지 존재한다.
1) mailbox를 구현한다.
2) 메세지를 mailbox를 통해서 send, recieve받는다.
3) mailbox를 destroy한다.
send(A,message) : send message to mailbox A , recieve (A, message) :recieve message from mailbox A
- Mailbox Sharing Issue
P1, P2, P3는 mailbox A를 share한다.
이때 P1은 메세지를 send하고, P2, P3는 메세지를 recieve한다.
이때 , P2, P3 중 어떤 프로세스가 P1이 전달한 메세지를 받을 까?
: Solution

1) Broadcasting : p2, p3가 모두 p1이 보낸 메세지를 받는다.
2) 하나의 프로세스만 메세지를 받도록 허용한다.
3) 보내는 프로세스가 reciever를 선택할 수 있도록 권한을 준다.
- Mailbox Synchronization
1) Blocking은 synchronus하다고 간주된다. non blocking은 asynchronus하다.
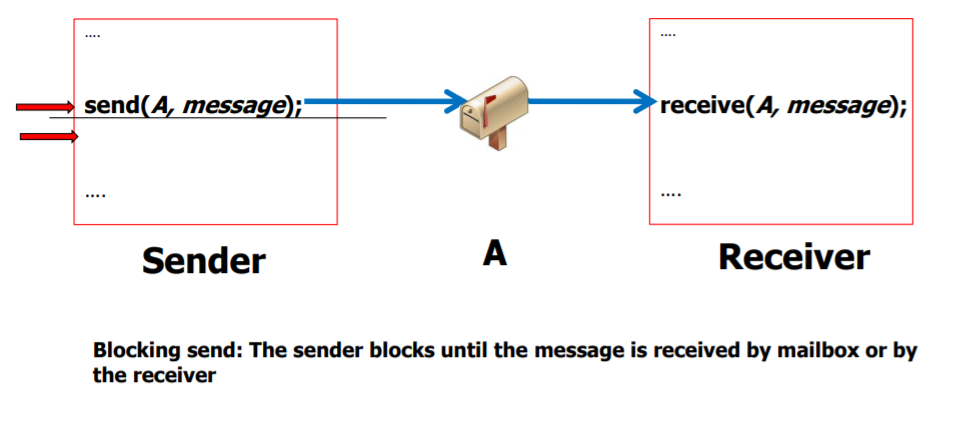
: blocking send: 보낸 메세지가 receiver에 아직 도착을 안했다면, 도착 할때까지 다음라인을 실행하지 않고 block되어있는 상태를 의미한다.
: nonblocking send: 반대로 sender가 보낸 메세지가 reciever에 도착하든 말든 line by line으로 다음 명령을 실행한다.
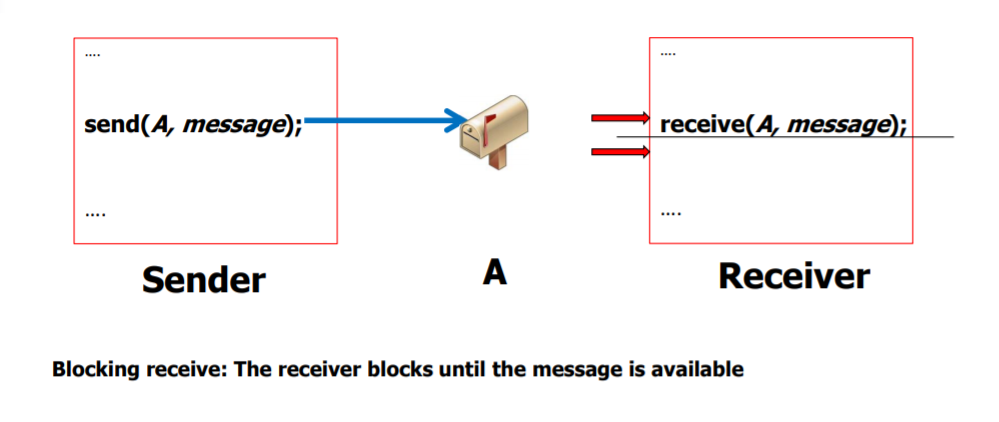
: Blocking recieve
: 해당 recieve 함수가 호출되었을 때 mailbox에 아무런 메세지도 도착을 안했다면 해당 recieve 함수 이후로 block된다.
해당 프로세스가 waiting 상태로 전환되었다는 의미. 해당 메일 박스에 메세지가 도착해서 메세지를 받을 때까지 block되고, 그 이후에 다음 line을 수행한다.
: Non blocking recieve
: 메세지가 아직 도착하지 않았어도 recieve이후의 다음 명령을 수행한다. 메세지가 없는 상태에서도 수행이 가능함.
- Queue of Message
: Mailbox의 크기에 따라서 구분이 될 수 있다.
1) Zero capacity: 메세지를 아예 받을 수 없는 경우이다.
-> 이때 굳이 메세지를 전송할 필요가 없고 뭔가 알려줄 필요만 있을때 , 이는 mailbox없이도 가능하다.
2) bounded capacity, unbounded capacity
: 메세지 받을 공간이 한정되어 있는지 아닌지 확인해볼 필요가 있다.

-> 그래도 총체적으로 message passing과 shared memory를 비교해본다.
<요 약>
1. Message passing
: 커널 내에 반드시 mailbox를 생성하고, send/recieve 함수를 메세지 전송, 받을 때마다 호출하여
system call 양이 많을 수 밖에 없다. (모두 system call을 호출해야 한다.)
=> 컴퓨터 끼리 소통하는데 편리하다( 다른 컴퓨터끼리 shared memory 설정 불가능)
=> 적은 양의 데이터를 교환하는데 편리하다.
=> system call을 매번 호출하므로 속도가 상대적으로 느리지만, synchronization에 신경 쓸 필요가 없기 때문에 구현이 훨씬 쉽다는 장점이 있다.
2. Shared memory
: shared 영역을 설정하고, attach, detach 할때만 system call 이 필요하다.
: shared memory가 훨씬 빠르다. 그렇지만 spin lock mechanism이 필요하므로 message passing mechanism이 구현이 더 쉬울 수가 있다.
message passing은 mailbox에만 넣어놓으면 커널이 알아서 synchronization 해주기 때문이다.
-> system call이 데이터 전송할때는 필요가 없고, 빠르게 많은 메모리가 처리가능하다.
-> 그렇지만 몇가지 protection mechanism을 필요로 한다! (뒤에서 언급할 예정)
'Computer Science > Operating system' 카테고리의 다른 글
| Ch 5-3) Process scheduling (0) | 2020.05.31 |
|---|---|
| Ch 5-(1),(2) Process Scheduling (0) | 2020.05.16 |
| ch4 - Threads& Concurrency (0) | 2020.05.04 |
| Operating system- chapter 1 (0) | 2020.04.10 |
| 3 little things- Limited Direct Execution 정리+ 번역 (0) | 2020.04.07 |