
#Operating Systems Examples
: 실제의 OS에 앞에서 학습한 내용을 적용해 보도록 하자.
- 기본적으로, Linux Scheduling은 Scheduling class에 의존하여 작용한다.
=> Scheduling class의 숫자에 따라서 우선순위가 적용된다.
1) 0- 99 까지의 우선순위 : Real-time class (우선순위가 높다)
2) 100-139 : conventional class (우선순위 낮음)
: 각 task를 클래스로 분류하고, 서로 다른 priority를 부여한다. ( 큐와 비슷하다)
: Multi-Level Queue와 유사한 방식으로 개발되고, 여러개의 큐로 나누어져 큐 안과 큐 간 스케줄링이 각각 존재한다.
- 각 프로세스들은 세가지 클래스로 분류된다.
1. SCHED_FIFO , SCHED_RR class- Real time process로 분류된다.
2. SCHED_NORMAL class- Conventional process
=> REAL TIME process 가 하나만 남아있더라도, Conventional process가 스케줄링이 불가능하다.
=> Real time process가 더 우선순위가 높다.
# 각 클래스의 Scheduling 방식은?
1. Scheduling of Real-time process
: 철저한 Priority 우선 방식으로, ( 0~99) 까지 부여되며, 우선순위 높은 Task가 무조건 먼저 CPU를 점유한다.
=> Priority를 가장 우선적으로 따지고, 그 이후에 FIFO class인지, RR class인지에 따라 프로세스들을 스케줄링 한다.

-> Ready Queue와 비슷한 Active array에 프로세스들이 우선순위 순서대로 CPU를 점유하게 된다.
: 이때, Priority가 가장 높은 프로세스가 먼저 스케줄링되는데, Priority가 같다면, FIFO 방식대로 먼저 도착한 task가 CPU를 점유하게 된다. ex) P1, P2가 우선순위가 같지만, P1이 먼저 실행된다.
=> P1이 실행을 다 마치고 빠져나올때까지 CPU를 점유하게 되며ㅡ 수행중에 나머지 프로세스는 절대 스케줄링이 불가능하게 된다.

-> 역시 Priority 기준으로 실행되고, 만약 우선순위가 같은 process가 있다면, FIFO class와는 다르게 우선순위 높은
Task 사이에 돌아가면서 일정한 Time quantum만큼 CPU를 차지하는 식으로 RR 방식으로 수행된다.
2. Scheduling of Conventional class
: 역시 priority를 우선순위로 따지며, CFS Scheduler라는 방식으로 스케줄링이 된다.
=> Kernel에서 CFS scheduler를 활성화시키려면, CONFIG_FAIR_GROUP_SCHED라는 명령어로 옵션을 설정한다.
1. Basic Idea of CFS
=> 이 스케줄링은 완벽히 공평한 Scheduling이라는 idea에서 출발한다.
: 각각의 프로세스는 CPU 할당비율을 가지며, CFS를 위해서는 어디서든 이 비율이 보장되어야 한다.

그렇지만, 현실적으로 하나의 CPU를 여러개가 나눠서 차지하는 것은 불가능하다. 특정 타임에 수행될 수 있는 process는 오직 하나이기 때문이다. -> 따라서, 이 비율에 맞춰서 돌아가면서 프로세스가 CPU를 차지하는 방법을 사용할 수 있다.

3000달러를 2:1로 나눠서 두 명의 worker들에게 지불해야 한다고 칠때,
1) 총 6일 동안 4:2로 A를 먼저 몰아서 페이를 지급하고, 그 이후에 이틀동안 B에게 페이를 지급한다면, B는 3일차에 아무것도 받지 못하고, 상대적으로 불공평한 분배가 된다.
2) 그렇지만, A,B,A 이런식으로 돌아가면서 페이를 지급하게 된다면, B도 3일 차에 한번 페이를 받을 수 있는 등 훨씬 공평한 분배가 될 것이다. 따라서, 비율을 맞춰서 번갈아가면서 지급하는 것이 더 공평하게 된다.

=> 각 프로세스마다 vruntime이라는 속성이 존재하는데, 이때 vruntime이 적은 task를 실행되고 있는 프로세스 다음에 스케줄링하게 된다.
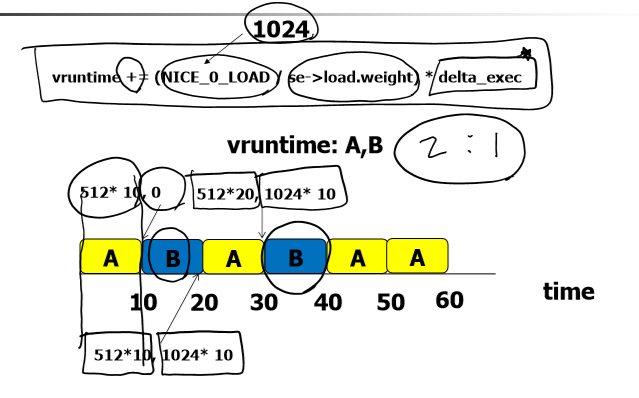
: vruntime += (NICE_0_LOAD (상수) / se->load.weight) * delta_exec
라는 식을 해석하자면, se->load.weight 변수는 weight 값이 각 task의 비율을 의미한다.
delta_exec 변수는 이전에 수행될 시간이다.
=> 따라서, 이전에 수행된 시간이 커질수록 vruntime은 증가하게 된다.
: 애초에 weight가 적으면 nice/ weight값이 작으므로, vruntime이 증가한다. (따라서 CPU에서 차지하는 비율이 적고, 우선순위가 낮은 프로세스라는 것을 의미한다.)
그 이후에는, 실행된 시간에 따라서 vruntime이 점점 증가하니, 계산식 에 따라 프로세스를 스케줄링하면 된다.
+) vruntime이 동일할 때는, 이전에 수행안된 task를 수행하면 된다.
#Algorithm Evaluation
1. Deterministic Modeling
: 미리 결정된 workload를 가지고, 각 알고리즘의 퍼포먼스를 비교한다.
ex) 바 형태의 Diagram인 gant chart로 각 알고리즘의 성능을 비교할 수 있다.

2. Queueing models
: Deterministic Modeling은 실제로 그런 수행 시간을 갖는다는 보장도 없고, 다양한 변수가 존재할 수 있기 때문에
예측 또한 어렵다, 따라서 다른 모델을 도입해 볼 수 있다.
=> 각 컴퓨터 시스템을 server의 network에 비유하고, CPU는 ready queue를 갖고 있는 서버라고 생각한다.
이때, Task arrival rate(도착률)과 service rate( CPU burst time)을 안다면, utilization, average queue length,
average waiting time등을 도출할 수 있다.
+) Little's Formula
: 모든 queueing 이론의 근본으로, 이론적으로 수학적 분석을 전개하기 유리하다.
Average queue length= average arrival rate * average waiting time
3. Simulation

=> 각 알고리즘을 프로그램에 넣고 돌림. 다른 모델과는 다른 결과가 나올 수도 있다.
4. Implementation
=> 직접 알고리즘을 구현해서 평가하는 것이 가장 효과적이다.
모든 simulation은 정확도가 부족할 수 있기 때문에, 직접 알고리즘을 구현하여 수치를 비교하는 것이
가장 정확하고 효과적인 method이다.
'Computer Science > Operating system' 카테고리의 다른 글
| Chapter 7. Classic Problems & POSIX API (0) | 2020.06.05 |
|---|---|
| Chapter 6. Process Synchronization (0) | 2020.06.03 |
| Ch 5-(1),(2) Process Scheduling (0) | 2020.05.16 |
| ch4 - Threads& Concurrency (0) | 2020.05.04 |
| ch.3-2,3 프로세스 생성, 종료 & IPC (0) | 2020.05.04 |