
#Swapping
: Swapping은 virtual memory를 사용하기 때문에 반드시 필요하다. 실제 physical memory보다 더 많은 공간을 사용하기 위해서이다. => 어느 시점에서는 메모리가 부족해져 memory에서 disk로 갈 수도 있다.
- Swapping을 할때 반드시 Address translation, memory protection을 실행하게 되고, 이를 위해서 메모리를 저장하는 세가지 기법에 대해 설명할 수 있어야 한다.
: Contiguous allocation, Paging, Segmentation
=> Process는 임시로 memory에서 swap out 되어서 backing store로 쫓겨 날 수 있고,
실행을 위해서 다시 메모리에 로딩 될수도 있다.
# 관련 용어
- Backing store: Swap-in, out을 위해서 할당되는 storage의 영역으로, Swap out 되면 memory에서부터 backing store로 옮겨서 저장되게 된다.
- Roll out, roll in: swapping 보다 하위의 개념으로, 우선순위를 기반으로 한 scheduling 알고리즘이다.
=> 우선순위 낮으면 roll out, 우선순위 높으면 roll in...
- 요청한 프로세스가 메모리에 없을 때에는, Backing store인 disk에 접근해야 한다.
=> 그런데, 메모리 접근 시간과 디스크 접근 시간은 단위 자체가 다르다. 디스크 접근 시간이 훨씬 느리다.
=> 미래에 접근할 프로세스는 가능한 physical memory 공간에 저장해 두는게 좋다.
#Swapping에 걸리는 시간

- Latency는 디스크 접근을 위해서 기본적으로 걸리는 시간이고, process 크기를 bandwith( 1초 동안 얼마만큼의 사이즈를 전송 가능한지에 관한 속도) 를 나눠서 프로세스를 전부 전송하는 시간을 더하면 swapping하는 시간이 걸린다.
- 따라서, latency가 8ms이라고 하고, 프로세스를 보내는 시간이 250ms라고 하면, 총 swap in/ swap out 하는 시간은
258 *2 =516ms 만큼 걸리게 된다,
=> Swapping하는 데 걸리는 시간의 대부분은 Disk latency가 차지한다. 따라서 애초에 필요한 데이터들은 physical memory에 저장해두면 시간도 매우 적게 걸린다.
: 따라서 가능한 미래에 접근할 프로세스는 main memory에 keep해두는게 좋다 : overhead를 줄일수 있기 때문이다.
# Contiguous Allocation
: 이는 프로세스를 연속적으로 저장하는 게 핵심이다. 따라서 프로세스의 크기와 시작주소만 알면 memory protection과 address translation을 쉽게 할 수 있다.
=> Contiguous allocation을 사용하는 시스템에서는 Resident Operating system ,User proesses으로 분리가 된다.
=> memory mapping(translation)과 protection을 위한 하드웨어
1) Relocation register : 프로세스의 시작 주소를 담고 있는 register이다.
=> Address translation은 Relocation register값에다 Logical address (offset==Logical address) 를 더하기만 하면 physical address가 되는 것으로 가능하게 된다.
2) Limit Register : 프로세스의 크기를 저장하고 있다.
=> Limit register의 값보다 logical address가 작으면 Memory protection을 위반하지 않은 것이다.
: 만약 Logical address가 Limit register의 값보다 큰 주소를 갖는다면 Memory protection을 위반한 것으로, 접근이 불가.
3) MMU: Logical address를 동적으로 매핑한다./ 이때 TLB를 참조하게 된다.
=> Relocation register와 Limit register값만 필요하다.
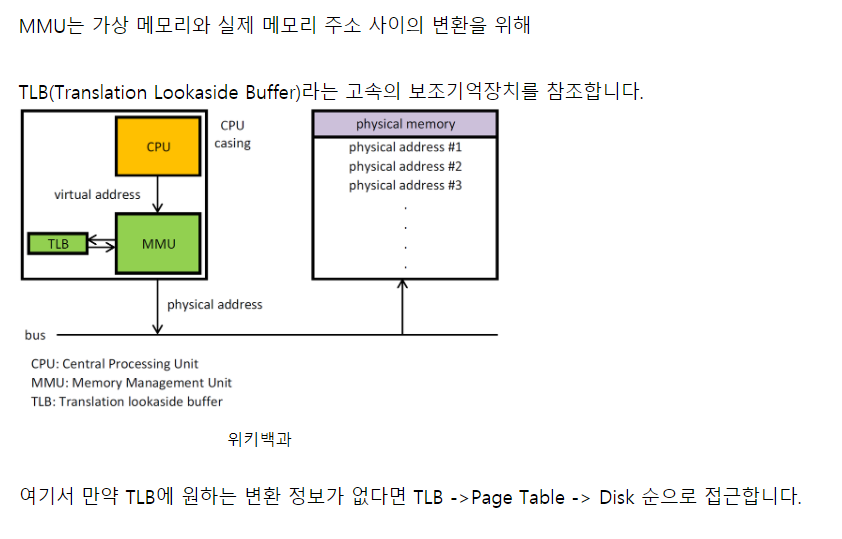
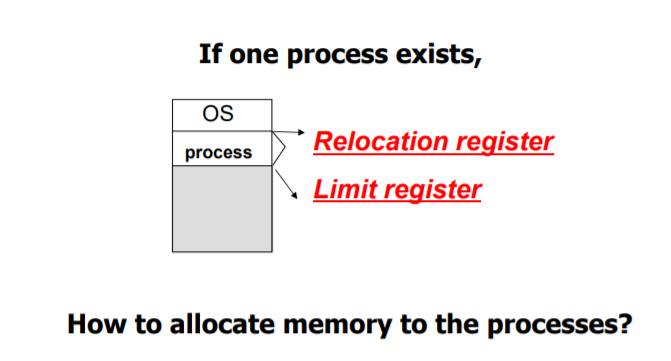
: 그림으로 정리해보자.
- Relocation register는 프로세스가 저장된 시작 값이고, relocation register값에다 logical address를 더한 값이
실제 Physical address값이 된다.
- 그리고 , Logical address값이 Limit register보다 작거나 같으면 현재 프로세스를 가리키는 것으로, memory protection이 가능하게 된다.
# How to allocate memory to the processes?
: 역시 메모리를 어떻게 프로세스에게 할당할 것인지가 굉장히 중요한 이슈이다.
=> 새로운 프로세스가 도착했을 때 어디에 어떻게 할당할 것인가?
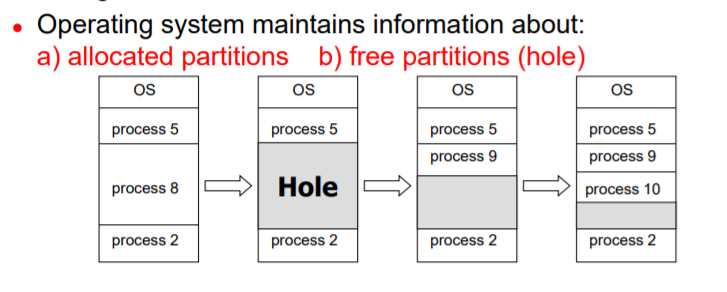
=> OS에서는 이미 할당된 partition과 빈 부분인 free partition hole에 대한 정보를 갖고 있다.
Hole은 memory가 현재 할당되지 않고 빈 상태인 부분이며, 다양한 사이즈의 hole이 memory에 분산되어있다
Q) 그렇다면, 프로세스 가 새로 도착하면 이 hole에 어떻게 할당하는가?
: 그림의 예시를 통해 살펴보자.
1) 프로세스 8이 terminate되면, 프로세스 8이 할당되었던 부분이 전부 해제되어 그 크기만큼의 hole이 생긴다.
2) 그리고 새로운 프로세스가 도착하는데, 이때 hole의 크기는 최소한 도착한 프로세스의 크기보단 커야 한다.
: Contiguous allocation이기 때문에 프로세스를 쪼개서 저장할 수 없고, 한번에 모든 프로세스를 연속적으로 저장해야 하는데, 이때 hole보다 프로세스의 크기가 크면 이 부분에 할당이 불가능 하다.
- 또, process가 들어갈 hole을 정해야 하는데, 이 dynamic storage allocation에는 세가지 방식이 있다.
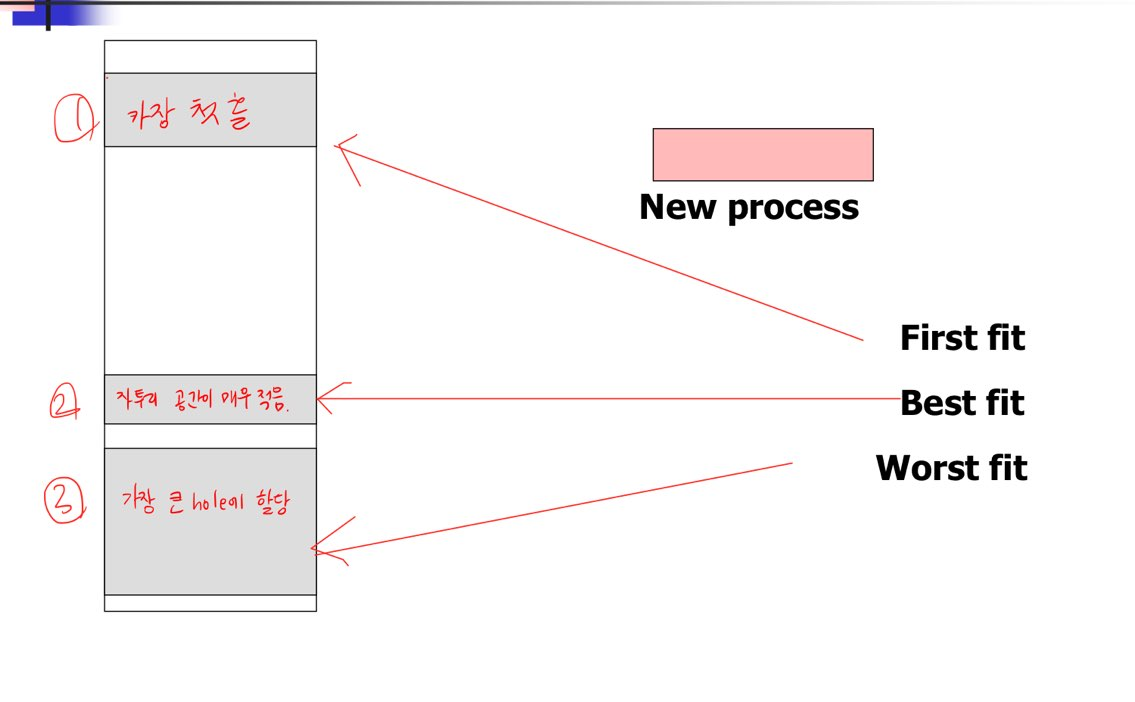
1) First-fit
: 제일 처음 hole에 프로세스를 할당 한다. ( hole 크기는 반드시 프로세스의 크기보다 커야 한다.)
2) Best-fit
: 프로세스 크기보다 같거나 큰 hole중에 가장 작은 hole에 할당한다.
: 남은 hole 부분이 제일 작다.
3) Worst-fit
: 가장 큰 hole에 할당한다.
: 남은 hole 부분이 매우 커지게 된다.
-Fragmentation
1) External Fragmentation
: Contiguous allocation에서 발생 가능한데, 비어 있는 공간의 합은 프로세스 크기보다 크지만, hole이 분산되어서 어떤 hole에도 프로세스가 들어갈 수 없는 상태를 말한다.
: 이는 비어있는 hole들을 모두 합쳐놓고, 큰 hole을 만들면 해결 가능하다. 이 기법을 Compaction이라고 한다.
2) Internal Fragmentation
: 자투리 공간이 남을 수는 있는데, 그 자투리 공간이 영영 사용되지 않는 문제를 말한다.
ex) 주로 paging에서 큰 홀에 프로세스를 집어 넣은후, 남은 공간이 매우 작아서 어떤 프로세스도 들어올 수 없고 방치되는 상태를 의미한다.
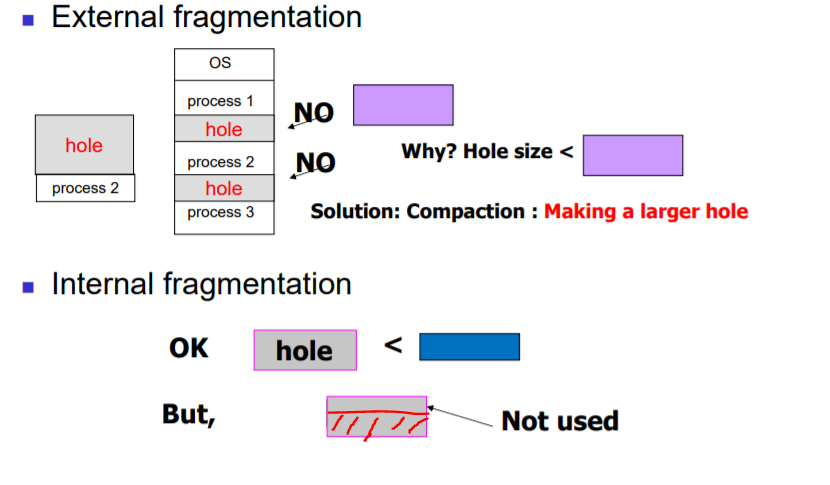
- External Fragmentation 경우에는 남은 hole들을 모두 합치는 compaction을 통해서 문제 해결이 가능하다.
: 왜냐하면 contiguous allocation의 경우에는 프로세스들을 쪼개어 저장하는 게 불가능 하기 때문이다.
- Internal Fragmentation은 hole에 프로세스가 저장된 이후로, 그 홀의 남은 부분이 영영사용되지 않는 문제를 의미.
#Paging
: Contiguous allocation과는 다르게, 연속적으로 프로세스를 저장할 필요가 없다.
1) Physical memory를 frame이라고 불리는 fixed-size block으로 분할한다.
2) Logical memory를 page라고 불리는 fixed-size block으로 분할한다. (Page와 Frame의 크기는 같다)
=> 프로세스가 도착하였을때, physical memory에 로딩하기 위해 빈 frame을 계속 추적하게 된다.
- 프로세스를 쪼개서 저장 가능하기 때문에 External Fragmentation은 발생하지 않지만, 남은 공간이 영영 활용되지 않는 문제가 발생한다.
: 따라서, 최대한 빈 공간이 남지 않도록 최소 페이지 크기를 할당해 주어야 한다.
: 만약 4kb의 크기 페이지에 7kb의 프로세스가 도착한다면, 4kb크기 페이지를 두개 할당 받고, 1kb가 남게 된다.
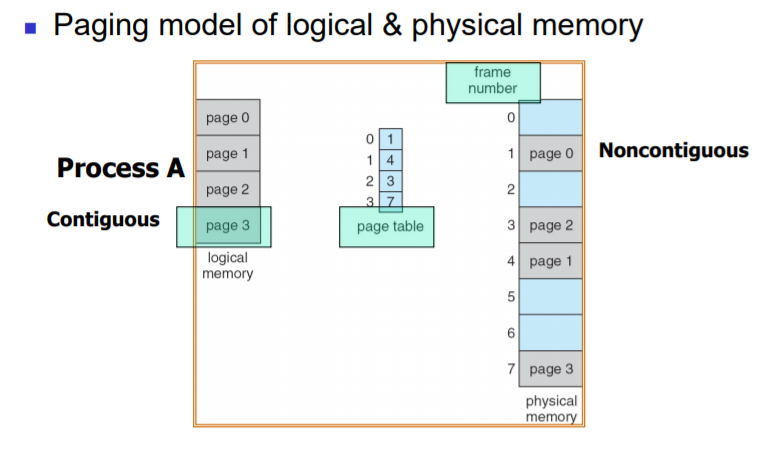
=> Page는 연속적으로 저장되어있다. 그리고 이를 physical memory로 translation하기 위해서는 반드시 page table이 필요하다. 이때, frame은 연속적으로 저장될 필요는 없다.
: 원하는 주소에 접근하기 위해서는 page의 크기와 offset을 알아야 한다.
1) 우선, page number를 갖고, page table을 통해서 frame number로 translation 해야 한다.
2) 그리고, 해당 frame의 시작 주소와 시작 주소에서 얼마나 떨어졌는지를 나타내는 offset을 더하면 physical address를 찾을 수 있다.
frame의 시작 주소는 : frame number x frame size( page size)를 곱하면 알수 있다.
그리고 거기에 offset을 더하면 physical address를 알 수 있다.

=> page 기법에서의 logical address는 2진수 하위비트 / 상위 비트로 알 수 있다. 이때, page bit의 자릿수만큼 쪼갠다.
만약 8bit size라면, 3자리 2진수이므로, 하위 비트가 3개가 되고, 상위비트는 2진수 자리-3bit가 된다.
0001 같은 경우에는 page size가 4라고 하면, 상위 비트는 page number, 하위 비트는 offset을 의미한다.
따라서 0001은 page 0의 offset 1만큼의 주소를 나타낸다고 볼 수 있다.

Paging 기법에서의 Logical address는 2진수 주소로 이루어진다. 이때, 총 address주소가 m개의 자릿수로 이루어져 있다면, 2^n개의 size를 가진 address는 n개의 하위 비트, m-n개의 상위 비트로 쪼개지게 된다.
- page number : page table에 접근하기 위한 index로 사용된다. physical memory로 translation될 때 frame number를 구하기 위해 사용된다. (base address구하기 위함)
-page offset : base address와 같이 사용되어, base address에서부터 얼만큼 떨어졌는지 offset을 나타낸다.
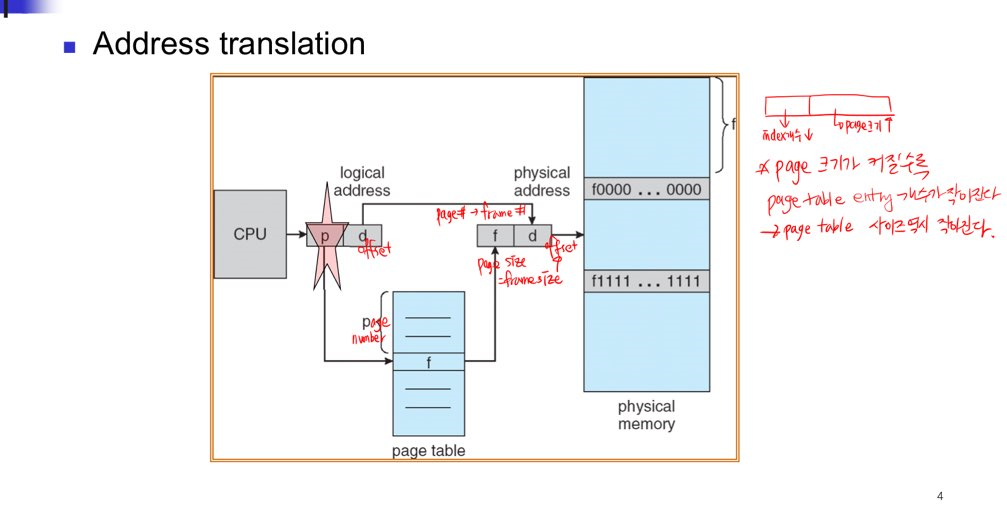
-> 그렇다면 paging 기법에서 address translation은 어떻게 이루어지는가?
1) page number를 page table을 통해서 frame number로 변환시킨다.
2) 이 frame number를 통해 시작 주소를 구하고, frame number에 offset을 더하면 physical address가 된다.
: 이 때, logical address의 bit 수는 정해져 있는데, page 크기가 커진다면 page개수가 줄어들게 되고,
따라서 page table entry의 개수가 줄어드므로, page table size도 줄어들게 된다.
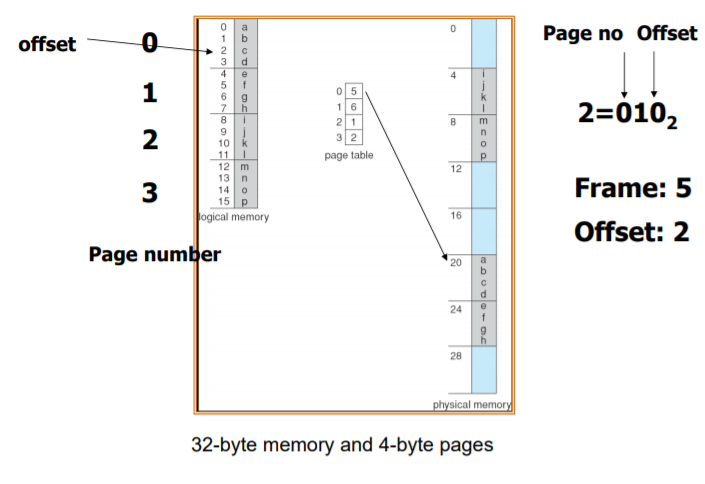
=> 010이라는 주소를 갖고 있을 때, 0번 페이지는 5번 페이지로 translate되므로, 20+offset 2를 더해주면
해당 physical addresss값에 접근할 수 있게 된다.
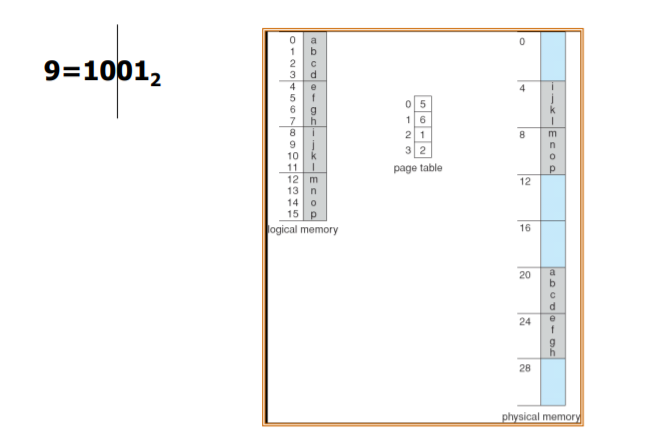
=> 역시 1001이라는 값을 갖고 있을 때, 페이지 number는 2 이고, 2는 1로 translate 되므로, 1번 frame의 시작 주소에서 offset 만큼 더해주면 해당하는 physical address에 접근할 수 있게 된다.

- External Fragmentation : 프로세스를 쪼개서 저장하는게 가능하기 때문에 발생하지 않는다.
- Internal Fragmentation : 한 페이지보다 프로세스크기가 작아서 남게 되면, 그 공간은 영영 사용되지 않게 된다.
: Internal fragmentation을 줄이기 위해서는 페이지 크기를 줄이는 방법이 있다.
: 하지만, page table entry가 커지게 되어 page table을 lookup하는 시간에 overhead가 발생하게 된다.
-> page는 요즘 전형적으로 4kb혹은 8kb 사이즈를 갖고 있다.
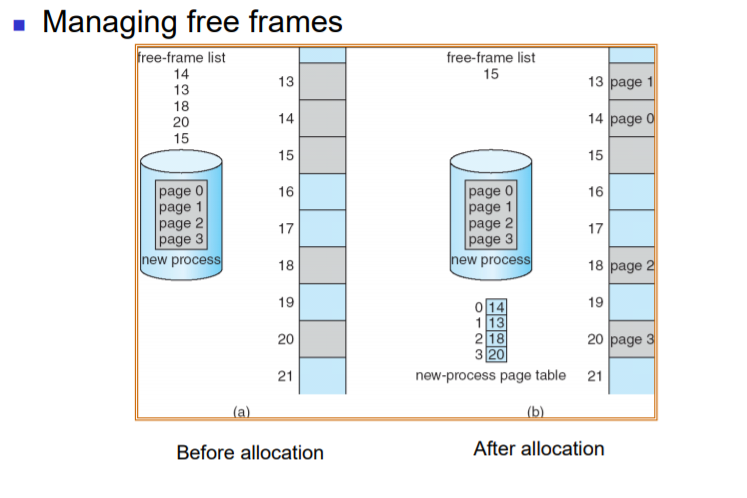
=> 쭉 free frame을 관리하면서 이미 frame에 페이지가 할당이 되었다면, page table을 update해준다
1) frame table
: 각 frame에 대해 할당되어있느냐, 비어있느냐를 체크하면서 비어있는 frame이 무엇인지 여부를 확인한다.
-> 따라서 page table을 update시켜주면서 비어있는 frame을 새로운 프로세스에게 할당시켜준다.
2) page table
: PCB내에 프로세스의 page table을 별도로 저장한다. 각 프로세스마다 page table을 따로 갖고 있기 때문이다.
-> 각 프로세스 는 별도의 virtual address space를 가지기 때문에, 이 address가 physical address로 매핑되는 곳이 모두 다르다.
# Paging- Hardware Support
: paging 기법을 돕는 하드웨어들이 몇 개 존재한다
1) Register
- Page -table Base register (PTBR) : 각 page table의 시작 주소를 담고 있는 레지스터
- Page-table Length register(PTLR) : page table의 길이(size)를 저장해두는 레지스터
: Page table을 통해서 address translation을 하게 되면, page table에 접근하고 physical memory에 접근하는 등
두번의 접근을 해야 한다. 따라서 이 시간을 줄이는 방법이 고안되었다.
2) TLB
: TLB란 page table의 일부를 TLB에 저장하여 빠르게 page table을 lookup 할수 있게 돕는 캐쉬이다.
원하는 페이지가 있으면 굳이 Page table을 lookup 하기 위해 메모리에 한번 더 접근할 필요가 없다.
-하지만 TLB에서 원하는 주소를 찾을 수 없다면, 다시 Page table을 lookup해야 하기 때문에,TLB의 hit ratio를 높이는 것이 매우 중요하다.
- TLB는 ASID (Address-space identifier) 라는 속성을 가질 수 있는데, TLB에 프로세스 ID라는 추가 정보를 더 가질 수 있다. 따라서, A->B 프로세스로 context switch할 때, 굳이 page table을 교체하지 않고, 해당 PID에 맞는 page number에 접근하여 frame number로 translation할 수 있다.
- TLB는 associative memory(고속 캐시)로, 이를 통해 parellel search가 가능하다는 데 있다.
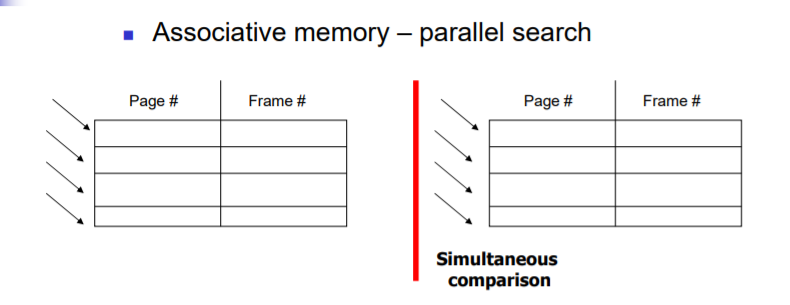
: 왼쪽의 경우에는 하나하나 page table을 lookup하면서 찾아야 한다.
: 하지만, associative memory 가 적용된 경우에는, parellel search가 가능하게 되고, 동시에 많은 page entry를 lookup할 수 있다.
=> Associative register인 경우에, frame number를 바로 구할 수 있지만, TLB에서 hit되지 못할 경우( TLB에 원하는 page number가 없을 경우)에는 page table에 한번 더 접근해야 한다.
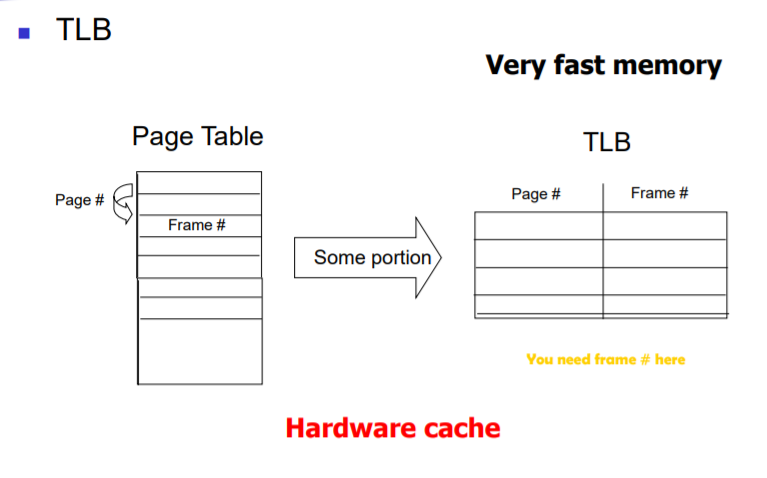
=> TLB에서는 많이 사용하는 page들을 잘 저장해서 hit율을 높여야 한다. 원하는 페이지를 못 찾을 경우에는 메모리에 다시 접근해야 하기 때문이다.
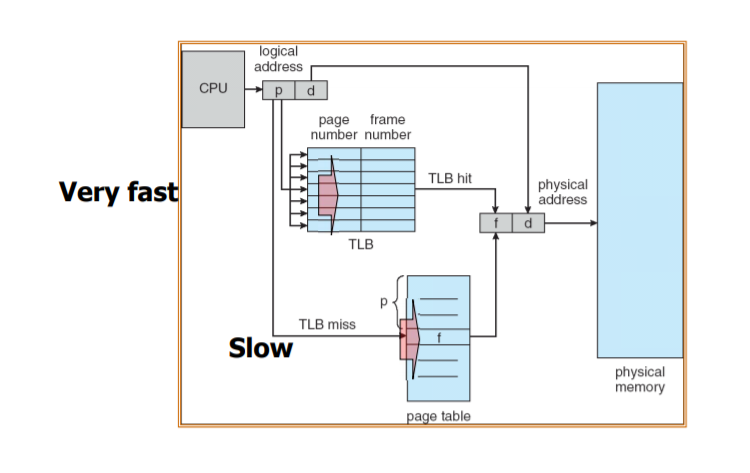
- TLB를 사용한 address translation의 경우에는, 우선 원하는 정보가 TLB에 있으면 바로 physical memory에 접근할 수있으므로 매우 빠르다.
-그렇지만 , TLB miss가 난 경우에는 Page table에가서 다시 Lookup해야 하므로 시간이 상당히 오래 걸린다


=> 실제 식을 통해 분석해 보더라도, hit ratio가 늘어날수록 EAT시간이 줄어들게 된다.
#Paging-Memory Protection
Paging 기법에서의 memory protection은 frame과 연관된 protection bit인 -> valid/invalid bit를 통해서 확인된다.
-valid bit
: 해당 페이지가 현재 프로세스의 logical address space안에 있다는 것으로, 접근이 가능하다.
-invalid bit
: 해당 페이지가 현재 프로세스의 logical address space에 없다는 것을 의미한다. 자기 영역이 아니므로 접근 불가능.

=> 우선 해당 프로세스는 page 5 까지밖에 존재하지 않는다. 따라서 page 6,7에 접근하는 것은 불가능 하다.
=> 그렇지만, valid한 page여도 페이지 크기만큼 프로세스가 할당되지 않을 수도 있다.
ex) 만약 page 4 까지의 크기가 10240 이라고 가정하고, page 5에서 저장된 크기가 10468이라고 했을 때,
page 5는 10468 이외의 영역은 본인 영역이 아니다.
=> 따라서 프로세스가 저장될 때, 마지막 페이지에서는 프로세스가 할당된 영역이 실제 페이지 크기 보다 적을 수 있다.
따라서 page table의 size인 PTLR를 참조하여 page table에서 logical address 10468 보다 큰 구간은 page 5영역이더라도 invalid할 수 있다는 것이다.=> Page table의 size를 통해 page limit을 알수 있다.
#Structure of the Page Table
: 페이지 테이블은 기본적으로 process마다 존재 해야 한다. 모든 프로세스마다 PCB를 갖고 있기 때문에 모든 프로세스 마다 갖고 있기 때문에 page table size가 커지게 되면 메모리 공간이 커진다.
=> 따라서, Hierarchical Paging, Hashed Page Tables,Inverted Page Tables를 통해 page table 크기의 문제를 해결할 수 있다.
#Large Address space
: 기존의 page table에서는 page size의 크기가 커질수록, page table의 길이가 줄어든다.
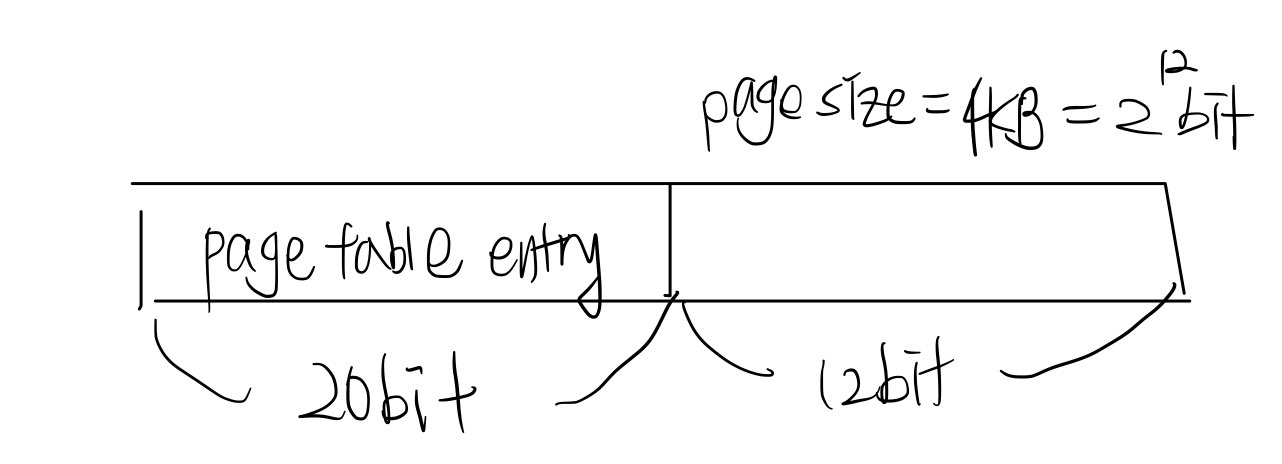
page size가 4KB인 경우에는 2^12bit이므로, 12bit로 offset을 표현할 수 있다.
그렇게 되면, page 개수 자체가 줄어드므로, page table entry의 개수가 줄어들게 되고, 총 page table 크기도 줄어든다.
=> page size는 주로 4KB이며, page entry size는 주로 4B이다. 그렇게 되면 총 페이지 table의 크기는 2^20*4MB이므로, 2^22 bit가 된다.
: 따라서 page table의 크기는 상당히 커지며, 이 페이지 테이블 사이즈를 줄이는게 상당히 중요하다.
=> page table의 크기를 줄이는데는 여러가지 기법이 존재한다.
#Hierarchical Paging
: Logical address space를 여러개의 page table로 나눈다. 가장 simple 한 기법은 two-level page기법이다.
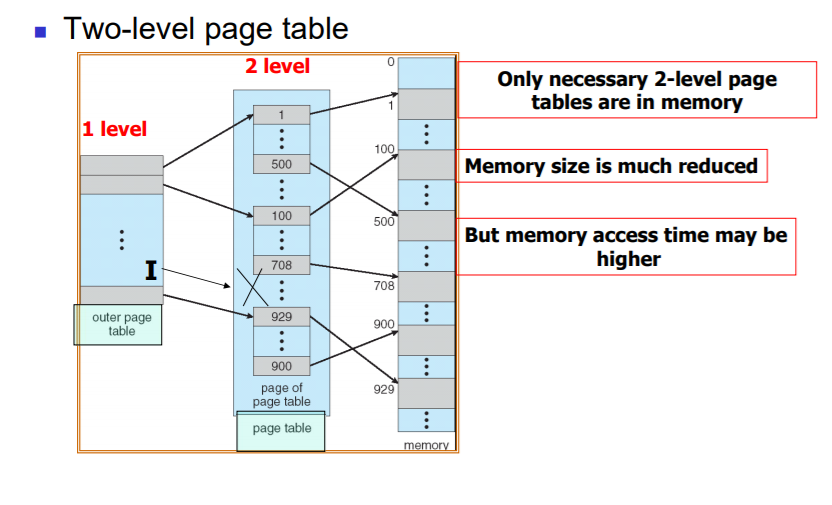
=> 20bit의 page table entry를 둘러 나누어 두 계층의 테이블 구조를 사용하게 된다.
: 2-level page에서의 address translation에서는 logical adress의 상위 비트도 두개 자른다.
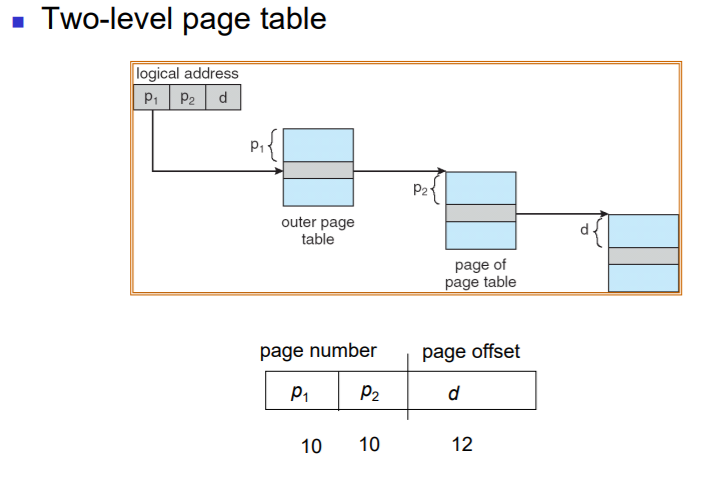
상위 portion의 상위 10 비트에서는 : level-1 page의 index를 담고 있다.
상위 portion의 하위 10비트에서는 : level-2 page의 index 를 담고 있다.
=> 상위 비트를 통해 level-1 page의 index로 접근하면, 해당 level-1 page에서는 level-2 page table에서의 시작 주소를 담고 있다. ( level-2 page는 page table이 여러 개로 나뉘어 있다. 따라서 필요한 page table에 접근하기 위해서는 반드시 outer page table을 거쳐야 한다.)
=> 그리고, 해당 level-2 Page table의 시작 주소 + 하위 비트를 통해 level-2 page table의 원하는 데이터에 접근할 수 있다.
하위 portion 12bit 에서는 frame에서의 offset을 담고 있다.
따라서 level 2 page를 통해 frame의 index를 알게 된 다음, 하위 portion의 offset을 더해서 physical memory에 접근할 수 있게 된다.
=> 따라서 level-1 page에서는 2^10개의 entry를 갖고 있고, 2번째 page table에서는 2^10개의 entry를 갖고 있게 된다. 그리고 frame의 개수는 2^12개이다.
=> 왜 Two level page가 memory를 줄이는 방법인가?
: 오직 필요한 부분만 메모리에 저장해 두기 때문이다 : level-1 page에서 invalid bit가 가리키는 부분은 아예 level-2 page에 저장이 되어있지 않다.
=> 하지만 페이지 테이블에 두번 접근해야 하기 때문에 Memory access time은 두 배로 늘어난다.
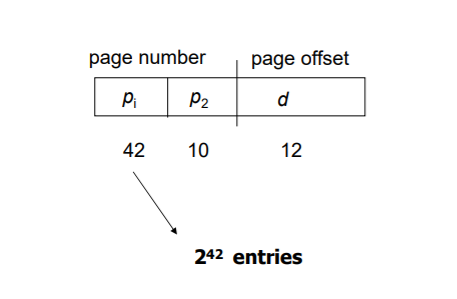
=> 64bit logical address space에서는, level-1 page가 2^42개 entry를 갖게 된다.
이는 상당히 많은 양이다.

=> 따라서, page table을 3개로 쪼개면 좀더 첫번째 level page table크기를 줄일 수 있다.
: 하지만 이는 level을 증가시킬수록 memory accesst time이 늘어나는 단점이 있다.
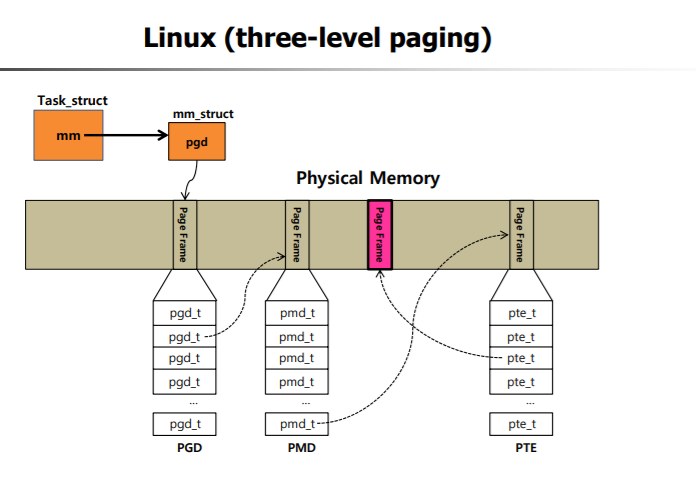
=> 리눅스에서는 메모리를 관리해주는 구조체 형인 PGD 안에 level 2 page의 시작 주소가 있다.
그 시작주소를 통해 PMD table에 접근하고, 상위 portion의 두번째 비트 부분의 index로 접근한다. 해당 index안에는
PTE의 시작 주소가 있다. 마지막 PTE를 통해 frame number를 알아내고, 하위 portion의 offset을 통해서 physical memory에 접근할 수 있게 된다.
=> 해당 frame을 찾기 위해서 세번 lookup 해야 한다는 단점이 있다.
#Hashed Page table
: 역시 page table 크기를 줄인다는 동일한 목적을 갖고 있다.
Virutal page number가 주어지면, 해당 hash table의 index로 들어가서, hash table을 lookup하게 되는데,
chain 형태의 data structure를 유지하고 있다.
: page number를 mod 형태로 나누기 때문에 한 page number에 해당하는 원소가 여러가지 일 수 있다.
=> 이를 chaining 형태를 통해 collision을 해소하게 되는 것이다.
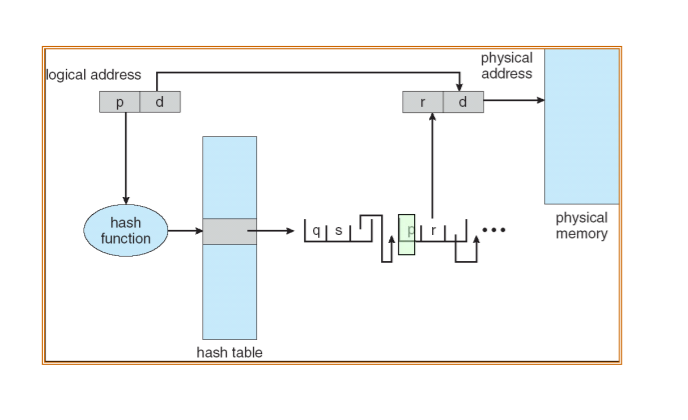
=> 해당 data structure는 다음과 같은 구조를 갖고 있다
1) 가장 앞선 field: page number
2) 두번째 field : 해당 page number와 match되는 frame number
3) 마지막 field : 다음 원소를 가리키는 포인터
제일 앞선 field를 확인하여 logical address의 앞부분의 page number와 일치되는 위치에 있는 값을 frame number로
결정한다.
=> 이 frame number에 logical address의 하위 portion인 offset을 더해주면, physical address값을 찾을 수 있다.
# Inverted page tables
: 기존의 page table size는 너무 크다.
=> 각 process마다 별도의 page table을 갖고 있기 때문이다.
=> PID를 추가하면 이 page table을 하나의 page table로 통합할 수 있다.
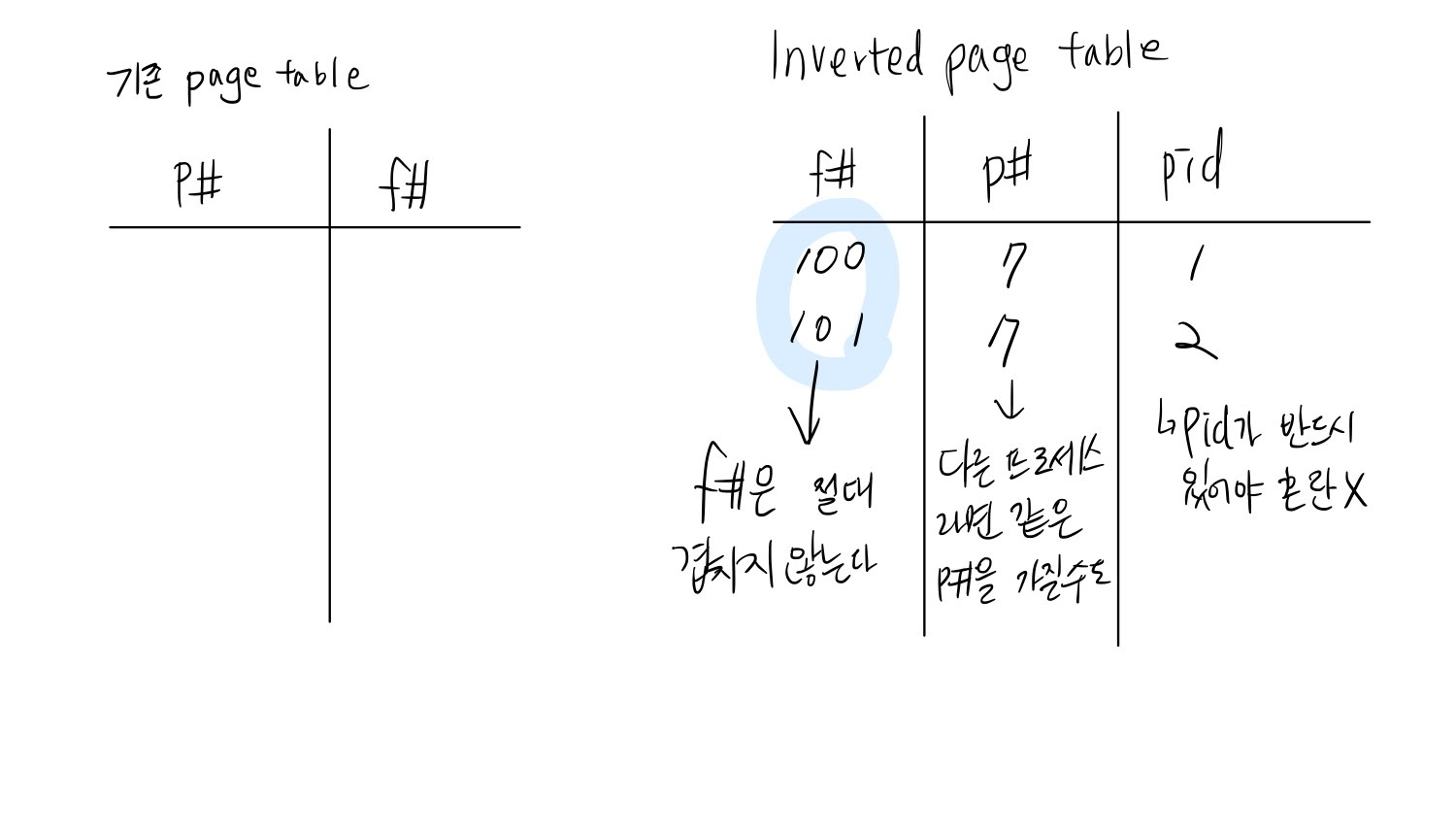
=> 각각 프로세스는 자기만의 logical address space를 갖고 있기 때문에, page number는 같을 수 있다.
하지만 PID로 구분이 가능하기 때문에, 서로 다른 frame에 할당해주면 된다. (PID없으면 반드시 혼란이 생긴다)
따라서 table index가 frame number이고, page entry값은 page number와 process id이다.
단점: PID를 찾기 위해서 모든 table을 뒤져야 한다는 단점이 있다.
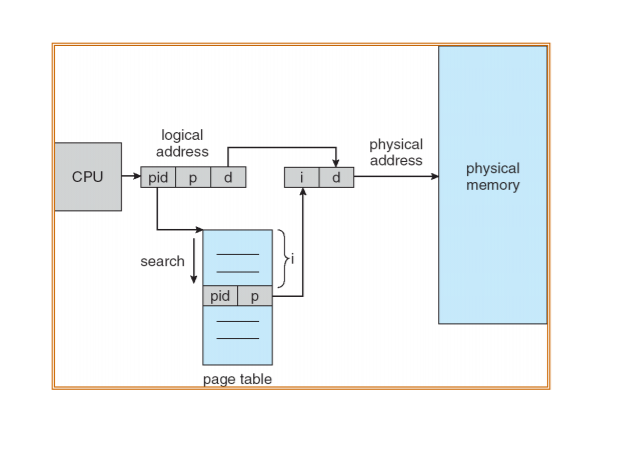
=> 우선 해당 pid를 쭉 searching한다음, 해당 pid에서 같은 page number를 갖는 부분을 찾으면, 해당 page entry의 index값을 return하면 frame number를 찾을 수 있다. 해당 frame number와 offset값을 더하면 physical memory가 된다.
: 모든 page table을 하나로 통합하므로, 메모리 공간을 매우 줄일 수 있다.
#Segmentation
https://copycode.tistory.com/108
운영체제 20장 - 메모리 관리(7) : 세그멘테이션(Segmentation) -
운영체제 20장 - 세그멘테이션(Segmentation) - 앞선 장들에서 페이징을 배우면서 프로세스를 일정 크기인 페이지 단위로 잘라서 메모리에 적재하는 방법을 알았다. 페이지는 정확하게 일정한 간격��
copycode.tistory.com
: 프로세스를 물리적인 단위인 페이지 말고 내용 단위인 segment로 자를 수 있는 segmentation 방법이 존재한다.
=> 프로그램들은 segment의 collection이다. 하나의 프로세스가 동작하려면 기본적으로 data, stack, code 세가지 세그먼트들을 항상 가지고 있다. : 각 코드 안에서도 내용이 다른 함수, 다른 루틴들이 있을 수 있다.
: 따라서 각 segment들의 크기는 일반적으로 같지 않다.
main program, procedure, method, function, local/global variables, stack. object... 같은 기능을 갖고 있는 부분끼리 조각내서 사용할 수 있다.
: 고기를 모두 같은 크기로 조각내어 보관하는게 아닌, 고기를 부위별로 보관하는 것과 같은 원리라고 보면 된다.

=> program은 5개의 segment로 분류되어있다. 각 segment들은 쪼개지 않고 연속적으로 저장해야 한다.
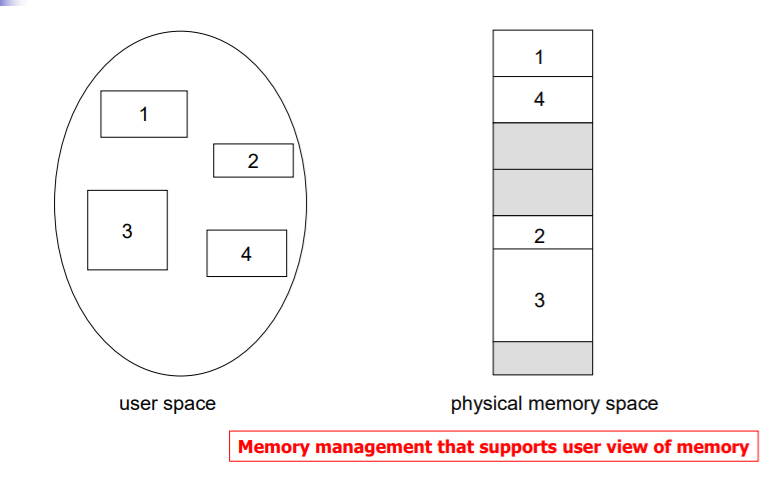
=> 단, 전체 프로세스 측면에서는 연속되어 저장되진 앟는다. segment 단위로만 연속적 저장하면 된다.
: 따라서 segmentation의 시작 주소만 알면 주소 변환을 쉽게 할 수 있다.

=> Segment 주소는 주로 두개의 문자열로 이루어져 있다. <segment number, offset>
: 예를 들어 (1,1000) 의 주소가 있다면, segment 1에 해당하는 base address값에 offset을 더하면 physical address가 된다. => 만약 offset이 limit addresss보다 작다면, memory protection이 된 것이다.
: 따라서, 각 segment들이 contiguous하게 저장되기 때문에, memory protection과 address translation이 쉽게 가능하다.

1) STBR은 segment table의 시작 주소를 가리킨다.
2) Segment table length register는 segment의 개수를 가리킨다.
따라서 segment number은 s<STLR이면 유효한 값이다.
'Computer Science > Operating system' 카테고리의 다른 글
| Ch 11. Mass Storage structure (0) | 2020.06.10 |
|---|---|
| Chapter 10) Virtual memory Management (0) | 2020.06.10 |
| Ch.9-1) Memory Management Strategies (0) | 2020.06.10 |
| Chapter 8. Deadlock (0) | 2020.06.05 |
| Chapter 7. Classic Problems & POSIX API (0) | 2020.06.05 |