
=> 이번 단원에서는 방대한 양의 데이터들을 저장하는 storage에 대해 배워볼 것이다.
# Disk Structure ( Hard-disk drive)
: 일명 HDD라고 하는, 주로 많은 컴퓨터에서 흔히 사용하는 물리적 disk storage이다.
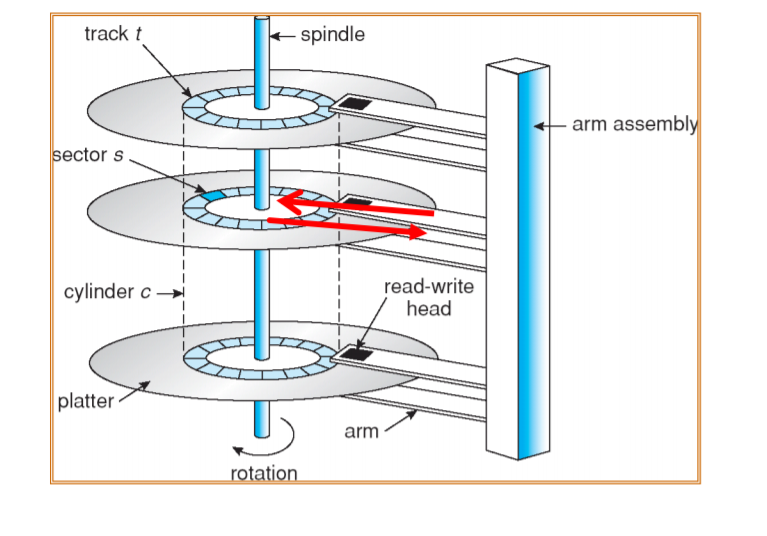
HDD 는 크게 spindle, platter, arm, arm assembly, read/write head로 이루어져 있고, platter안이 여러개의 track으로 구성되어있다. track의 최소 단위를 sector라고 한다.
1) Spindle
: 시스템 부팅 후에 Disk의 내용을 읽고 쓰기 위해서는 반드시 Spindle이라는 회전축으로 disk를 회전시켜야 한다.
따라서, 노트북을 절전 모드로 돌리거나 하면 spindle의 회전을 멈춰서 데이터를 읽고 쓸수 없게 한다.
2) Platter
: 데이터들이 집합되어있는 원형 모양의 disk이다. 각 Disk들은 여러개의 track으로 이루어져 있다.
이때, track의 최소 단위는 sector로, sector는 각 데이터들을 담고 있다.
3) Arm
: arm은 직접 데이터를 읽어들이는 부분으로, arm의 끝에 read/write head가 위치하여 실질적으로 data를 읽어들인다.
4) Cylinder
: 각 disk에서 동일한 거리에 있는 세개의 track들을 연결해보면 원통 모형처럼 생겼기 때문에 cylinder라고 명명한다.
=> read/write head가 서로 다른 cylinder를 가리킬순 없다. arm들은 서로 동기화되어 같은 cylinder를 가리킨다.
Q. 실질적으로 Data를 읽어들이는데 시간이 얼마나 걸리는가?
A: Seek time+ Rotation Latency + Transfer time을 합한 시간 만큼 걸리고, Seek time이 가장 중요한 keypoint이다.
1) Seek time
: head가 요청한 sector가 위치한 track까지 arm을 뻗는데 걸리는 시간
=> 가장 오래걸리는 시간이며, seek time을 줄이는게 access time을 줄이는 key이다.
- Seek time 은 Seek distance에 비례하게 된다. seek distance가 멀수록 arm이 움직일 거리가 증가하기 때문이다.
-시간당 데이터가 전송된 비율인 "Disk bandwith" ( 총 전송된, 읽고 쓴 byte개수/ 총시간) 을 늘리기 위해서라도 access time을 최소화해야 한다. 이때 seek time을 줄이면 access time이 전체적으로 줄어들게 된다.
=> Seek time을 줄이기 위한 Disk scheduling이 많이 개발되어 있는 상태이다.
2) Rotation latency (delay)
: 해당 sector가 head밑으로 와야한다. spindle을 통해 돌리면서 sector를 찾게 된다.
3) Transfer time
: 데이터를 실제로 읽고 전송하는 시간
# Solid-State Disk (SSD) 의 특징
: SSD란 반도체 chip 형태의 disk drive로, HDD처럼 기계적인 disk 움직임은 전혀 필요가 없다.
: HDD보단 고장도 덜날 수 있고, 매우 빠르고, 안정적이므로 반드시 필요하다.
: 그렇지만 HDD보다 훨씬 비싸고, 용량도 적으며, 더 짧은 수명을 갖고 있다 .
Q) SSD는 수명이 왜 짧은가?
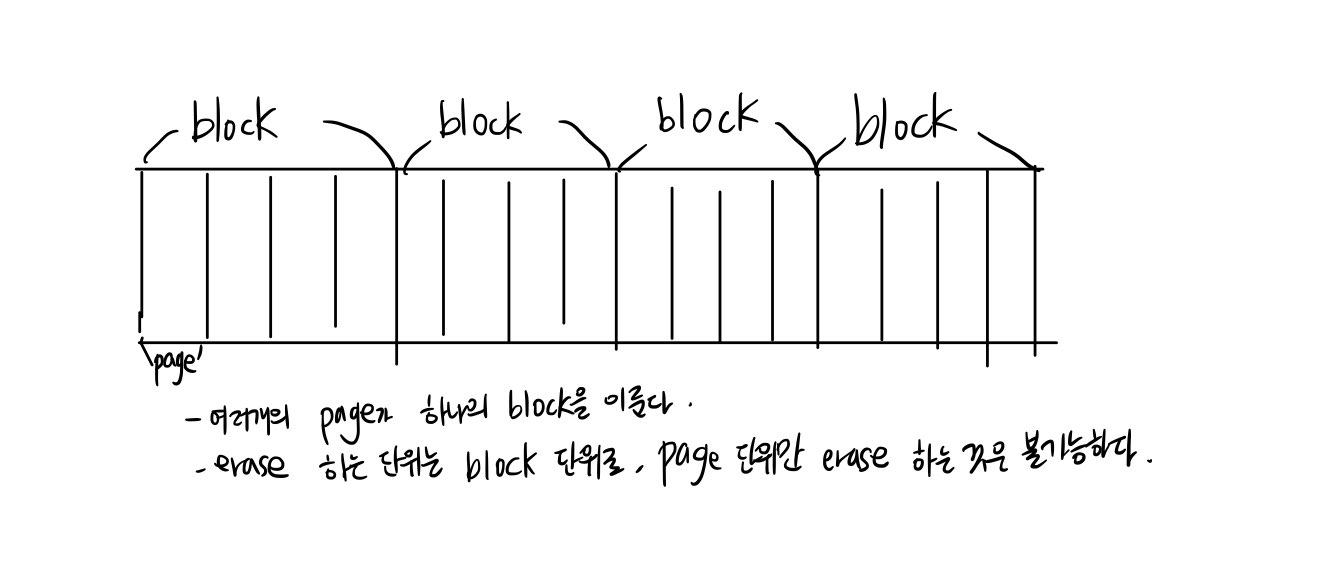
A) SSD는 block단위로 구성되어있고, 각 block에 write할수 있는 횟수가 제한되어있다 ( 따라서 조금이라도 한 블록을 많이 write하게 되면 바로 못쓰게 된다.)
=> 따라서 각 block에 균등하게 write 해서 균등하게 닳게 하는 정책이 매우 중요하다. 이를 wear-level 기법이라고 한다.
Q) SSD에는 어떻게 read/write하는가?
: SSD에는 block 단위로 구성되어있고 , block안에 또 read/write를 하는 작은 단위인 page가 존재한다.
- SSD는 overwrite가 불가능하다. 위에 덮어서 또 쓰는게 불가능하므로, SSD를 싹 지우고 새로 정보를 입력해야 한다.
: 그렇지만, 읽고 쓰는 단위가 Page인것과 다르게 SSD는 block 단위로 지워진다.
- SSD에는 write할수 있는 횟수가 정해져 있다. 그것은 즉 erase를 계속 해가면서 해당 cell이 닳기 전까지 erase하고 새로 write할수 있다는 것을 의미한다. 따라서 Wear-leveling 정책이 반드시 존재해야 한다!
: " ERASE BEFORE WRITE " 정책을 잊지 말자!!
Q) 그렇다면, SSD에서는 데이터 공간의 확보를 어떻게 하는가?
A) Garbage collection을 이용해 dead data, trash data가 너무 많이 쌓이면 한번씩 싹 밀고 빈 공간으로 바꿔준다.

=> SSD의 페이지에는 세가지 속성이 존재한다
1) Live : empty space에 데이터가 처음 들어와 저장되어있는 상태
2) Empty : 아무것도 저장되지 않고 비어있는 상태
3) Dead: 이미 저장이 된 데이터가 한번 더 탐색되었을 때, 그 데이터는 위에 또 overwrite가 불가하므로 Trash data로 처리한다.
- 저장 과정
1) 데이터를 넣을 빈공간을 탐색한다. 이미 저장되어있는 부분은 dead data로 바꿔주면서 빈공간을 찾는다.
2) 빈 공간을 찾으면, 그곳에 데이터를 저장하고 state를 live로 바꿔준다.
3) 그렇게 빈공간을 점점 채워나가다 저장공간이 좀 부족하다 싶으면, block 단위로 dead data가 쌓여 있는 부분을 한번 싹 밀어주고 empty state로 바꿔준다.
- Garbage Collection이 필요한 이유는?
: erase before write 정책이 있기 때문에, 새로 저장하기 전에 block 단위로 dead data를 erase하고 새로 들어갈 데이터의 저장 공간을 확보하기 위해서이다.
<SSD summary>
1. Erase before write : overwrite는 금지되어있음
2. erase unit은 block이고, read/ write unit은 page이다
: 위 두 특징 때문에 garbage collection이 필요하다.
=> Overwrite가 안되기 때문에 특정 컨텐츠가 동일 페이지에 있다는 보장이 없고, 계속 움직일 수 밖에 없다.
: 특정 위치에 overwrite에 안되므로, OS에서 보든 page 위치가 바뀔 수 있기 때문에 그를 추적하는 mapping layer인
Flash transition layer를 하나 놓는다.
3. Wear leveling을 통해서 각 block을 균등하게 write해줘야 한다.
# Disk Attachment
: 컴퓨터를 사용하다 용량이 부족하여 새로운 disk를 장착해본 경험이 다들 있을 것이다.
=> 이때, 새로운 disk를 사용하기 위해선 어떻게 해야 할까?
1) Host- Attachment storage
: Disk를 사용하기 위해선 Host page에 미리 attach 해줘야 한다.
: 이때, PC에서 일반적으로 HDD를 장착하는 방식은 SCSI라는 bus를 I/O bus 로 사용하는 것이다.
+) Bus란 데이터를 각 장치 사이에서 통신할 수 있게 해주는 system이다.

=> SCSI bus는 최대 16개의 disk를 장착 가능하다.
2) NAS ( Network- Attached storage)
: 사무실이나 회사 같은 곳에서는 storage를 모아두고 직원들이 network를 통해서 storage에 접근할 수 있게 한다.
NAS는 bus와 같은 local connection대신에 network protocol을 사용한다. NAS에 저장된 데이터를 client가 LAN이나 WAN을 통해서 접근하는 방식이다.

3) SAN (Storage Area Network)
:Server 에 저장된 storage들을 SAN이라는 protocol을 사용해 접근하게 된다.
: Network protocol 보다는 storage protocol을 사용하며, storage들은 host들에게 dynamic하게 attach될수 있다.
: 주로 FC라는 high-speed serial architecture를 사용한다.

<Disk Attachment Summary>
| Host Attached | 가장 일반적으로 쓰이며, I/O bus를 통해 Storage에 접근한다. 주로 HDD에서 사용. |
| NAS | Storage를 network 방식으로 접근하는 것이다. 일반적인 네트워크 protocol을 주로 사용하게 된다. |
| SAN | Storage array에 접근할 때 쓰는 protocol으로, Storage protocol을 주로 사용한다. |
+) SAN과 NAS의 차이점
: NAS에서 client가 일단 network를 통해 server에 먼저 접근한 후, 서버에 저장된 storage에서는 SAN을 이용해 Storage array에 접근하게 되는 것이다.


: head에서 가장 가까운, 가장 짧은 seek time을 나타내는 request를 우선적으로 처리한다.
=> starvation 발생가능하다. request는 계속 도착하는데 계속 head 주변으로만 도착한다면 head에서 먼 request는 아예 실행조차 되지 않는다.
: Optimal 한 방식은 아니다.

한 방향으로 쭉 훑었다가, 맨 끝에 다다르면 다시 다른 방향으로 바꿔서 훑어 나가면서 request들을 처리한다

: Scan과 비슷하지만, 단방향으로만 처리하며, 끝에 다다르면 다시 반대편 끝으로 가서 그 방향대로 request를 처리한다.

: request가 없을 경우에는 끝까지 가지 않고, 해당 방향에서 더이상 처리할 request가 없으면 방향을 튼다.

: one-direction look algorithm이다.
# Disk Management
-Disk Formatting
: disk formatting에는 두가지 종류가 있다.
- 첫번째는 우리가 흔히 말하는 포맷인 Logical formatting이 있다.
: 이는 초기 file system을 만드는 과정을 의미하는 것으로, initial file system을 만들기 위해서는 해당 데이터를 다 지우고 초기화해주어야 한다. file system 없이는 데이터를 읽고 쓸수 없다.
- 두번째는 Low-level formatting으로, Physical formatting이라고도 한다.
: 이는 disk를 sector단위로 분할하는 것으로, head가 read/write하게 만들어준다.
- Boot block
: Disk storage의 앞부분에는 주로 boot block이 위치하고 있다.
: boot block은 부팅할 때 중요한 정보들이 들어있는 lock으로, boot strap이 ROM에 내장되어있는데, Boot strap loader가 boot block을 메모리에 로딩하고, 제어권을 boot block에게 넘겨주게 된다.
- Swap space
: swapping을 하면서 swap out 된 페이지가 위치하는 곳을 swap space라고 하는데, backing store라고도 불린다.
: 그렇다면 swap space는 어떻게 관리될까?
1) normal file system밑에서 관리 될 수도 있다.

2) 또는 별도의 파티션을 두어서 해당 영역을 관리할 수도 있다
: 그러면 이 파티션만 관리하면 되는데, 이때는 별도의 swap space manager가 존재하게 된다.
<Swap space를 관리하는 mechanism : swap-map mechanism>

=> swap space는 page slot과 swapmap으로 이루어져 있다.
: page slot들은 swap out된 페이지들을 담고 있는 영역이다.
: swap map은 해당 swap out된 페이지를 사용하는 프로세스의 개수이다. => 한 페이지를 여러 프로세스가 사용 가능.
# RAID( Redundant Array of Inexpensive(Independent) Disks)
: RAID란 여러 디스크를 병렬적으로 구성하여, storage 용량과 throughput을 늘리기 위한 저장장치를 말한다.
: I/O 연산이 많이 일어날수록 하나의 disk로만으로는 부족하다. 따라서 여러 디스크를 병렬적으로 연결하여 array of disk를 만들어내게 된다.

: 그림과 같이 여러 disk를 병렬적으로 연결하였을 때, 한 disk의 속도가 300mb/s라고 추정하였을때, 다른 disk 여러개를 부착하면 최대 2100mb/s의 성능 (실제론 그것보단 훨씬 못하다.) 로 향상시킬 수도 있다.

: RAID를 통해 얻는 이점에는 성능을 향상시키고, disk 가 고장나더라도 데이터를 잃어버리지 않게 할 수 있는 fault-tolerance 기술을 적용시킬수 있다는 것이다.
- Throughput 향상 : Striping 기법을 사용한다. Striping은 하나의 파일을 여러개 disk에 걸쳐서 저장하는 것이다.
- Fault-tolerance 기법: 데이터를 복제하여 저장해두는 Mirroring 기법과, parity block을 사용하는 parity 방식이 있다.
=> Disk를 병렬적으로 연결할 때, redundant라는 용어를 사용하는 만큼 중복된 부분이 있어야 하는데, 여러 디스크 사용시 고장 확률이 있으므로 해당 데이터를 잃어버릴 수 있다. 따라서 이를 복구하기 위해서 저장된 데이터를 복사해서 저장해놓거나, parity 정보를 사용하는 것이다.

RAID에서는 A라는 파일을 A1,A2,A3... 등으로 여러개 disk에 분할하여 저장한다.
이를 Striping이라고 하는데, striping의 unit size에 따라 bit-level striping/block level striping으로 나누게 된다.

1) Bit-level striping
: striping의 unit size가 bit로, unit size가 작으므로 파일이 작게 쪼개진 것이다. 실제로 bit size만큼 쪼갠건 아니지만 그만큼 데이터를 잘게 쪼갰다는 의미이다. (storage의 최소 단위는 sector)
: Bit-level striping같은 경우에는 디스크의 각 데이터들이 동시에 synchronized되어 working된다
: disk가 synchronized되어 data를 read/write한다.
2) Block-level striping
: 동시에 모든 disk가 작동할수도 있지만, 특정 디스크에만 read/write하는 것도 가능하다.
#Fault Tolerance
: Disk 하나는 신뢰성이 높은데, disk개수가 많아지면 많아질 수록 고장날 확률이 늘어난다
-> 서버같은 경우에는 클라이언트의 요청이 올때마다 I/O를 해야 하기 때문에 disk고장 확률을 무시할 수가 없다.
=> 만약 disk한개의 mean time to failure(MTTF: 고장이 날때까지 걸리는 시간) 100,000시간이라고 하면,
: 100개의 disk의 MTTF는 100000/100= 1000hours이다. 점점 고장날 확률이 높아지게 된다.
: 예를 들어, gmail을 이용할때 내 메일이 누락되거나 사라지는건 서버 상에서 큰 문제가 된다.
=> 오직 해결책은 Redundancy, 데이터를 중복하여 여러 군데에 저장해 놓는 것을 의미한다.
: Mirroring방식, Parity방식 두가지 방식을 사용할 수 있다.
1. Mirroring 방식

한 디스크가 고장이 났을 때에, 만약 다른 디스크에 해당 디스크의 정보들을 복제해서 저장해두었다면, 그대로 그 디스크에 접근하여 사용하면 된다.
=> 만약 복제 디스크도 고장이 났다면, 데이터를 아예 손실하게 되므로, 원래 디스크가 고장이 나면 남아있는 디스크에 복제된 디스크를 이용해 해당 데이터를 모두 옮겨놓는다. 이때 해당 데이터를 옮겨 복구하는 시간을 Mean time to Repair라고 한다.

: 이 복제 디스크에서 남은 디스크로 A데이터를 옮기는 Meantime to repair 시간에 복제 디스크가 고장이 난다면, 아예 데이터를 Loss하게 되는 것이다.

: 하지만, Mirroring의 MTTR를 계산해보면 57000년에 한번이므로, 상당히 안정적이긴 하다
=> 단점은, 하나의 파일을 두번 저장하므로 storage용량도 두배라는 것이다.
# Parity 방식의 Fault tolerance

# Raid의 종류
: Raid에도 여러가지 종류가 있다. step별로 어떤 장단점이 있는지 알아두도록 하자.

1) raid 0에서는 아예 디스크가 중복된 부분이 없으므로, disk가 고장났을때 복구가 불가하다.
2) Raid 1에서는 모든 disk가 mirrored된 상태이고, storage 용량이 원래 디스크 사이즈의 두배 만큼이 필요하다.

: Raid 3,4에서는 parity disk+ bit, parity+ block 형태로 각각 저장되어있고, 만약 disk가 고장이 안나면 parity disk는 아예 사용되지 않으므로 디스크 하나의 bandwith용량을 날리는 것이다.


Raid 5: parity를 분산해서 저장해놓으므로, 디스크 고장이 나지 않더라도 모든 디스크를 효과적으로 사용할 수 있다.
Raid 6: 디스크가 두개 이상 고장나도 복구가 가능하다.
#Additional Concepts
1) Hot spare
: 자동차를 몰고 다니면 spare tire를 갖고 다니는 것과 비슷하다. 고장난 디스크를 대체하기 위해 spare disk를 두는 것이다. 평소에는 사용하지 않는다.
2) Rebuilding
: 만약 disk가 고장나면, 복구하는 과정에서 rebuilding data가 hot spare에 저장된다.
-Raid에선는 Fault tolerance와 Raid 의 level의 특징을 기억해두자.
'Computer Science > Operating system' 카테고리의 다른 글
| Chapter 10) Virtual memory Management (0) | 2020.06.10 |
|---|---|
| 9-2) Memory Management strategies (0) | 2020.06.10 |
| Ch.9-1) Memory Management Strategies (0) | 2020.06.10 |
| Chapter 8. Deadlock (0) | 2020.06.05 |
| Chapter 7. Classic Problems & POSIX API (0) | 2020.06.05 |